For decades, scale gave large telcos purchasing power, infrastructure reach, extensive capability and millions of customers. It became one of the world’s most powerful and durable business models. But scale and complexity has created thousands of dependencies across OSS, BSS, networks, processes, vendors and people. Clay Christensen showed that disruption often begins with something that […]
Since OSS were first built, they’ve been designed around the belief that more complete information creates better operations. That belief made sense when they were designed by Engineers for Engineers. When network, service, customer, inventory, topology and assurance data was scarce, fragmented and hard to access. The organisation with the best information usually had the […]
Telco keeps talking about being scared of an imminent skills cliff. But perhaps the real problem is not just that experienced people are leaving. It’s that the industry has stopped feeling like the natural destination for the next generation of brilliant minds. Meanwhile, the industry’s hardest problems – automation, AI-native operations, complex transformation, data integrity, […]

Phone books now look like a relic from another era. Stone. Cold. Dead. But they were once one of the most powerful business growth engines in the world. Owned by telcos! As they declined in importance, Telcos didn’t just lose a directory. They totally forgot they were matchmakers. Phone books were never just paper directories. […]

We’re releasing our latest report today. Click on the image below to download it. Why are transformation approvals (eg business case approvals, vendor selections, project transformation decisions) forced to look perfect when delivery is anything but? That is the quiet contradiction at the heart of many (most?) digital transformation programmes. We build business cases as […]
With MWC upon us again, I thought I’d pose a question about how our industry, and the 500+ OSS/BSS vendor market within it, is currently evolving. Telcos spend billions on transformation programmes every year. They talk about massive disruption like cloud-native stacks, open architectures, AI-driven automation and next-generation digital experiences. On paper, it sounds like […]
Quants have become the rockstars of modern share trading – extracting powerful signals from oceans of data at near real-time speed. Trading firms invest billions in them and in infrastructure that will give them even the slightest timing edge. Yet while telcos drown in dashboards, the next competitive advantage may belong to the “NOC-star” – […]
One of the things I find incredibly interesting when I look at the Simplified TAM diagram below is that of each of the arrows indicating a workflow, only one has systems that aren’t really designed to manage the operational workflow. Assurance has trouble tickets Fulfilment has service orders Field operations has work orders Even billing […]

What happens when a Software Engineer, Enterprise Architect and Network Ops Engineer walk into a bar?….. . You know that head-slap moment when you realise software is more hindrance than help? I had one such experience back in circa 2005, when I watched a genuinely brilliant network ops engineer spend an entire afternoon navigating tools […]

Whether we like it or not, most of us judge books by their covers. Sometimes that’s visual. Sometimes it’s the title. But here’s a thing I find interesting. Having written a couple of books myself, a lot of thought goes into choosing the title to resonate with the viewing audience. And yet, sometimes a title […]
The last four articles have explored the way some telcos are using AI technologies counter-productively today – AI entanglement, transformation planning, dependency visibility and the hazards of autonomy. The final question for this article is whether telcos can or will ever earn the right to unplug their legacy OSS. In Part 4, we ended with […]

Many (myself included), believe that recent progress in AI-based technologies should accelerate digital transformation (even if only by inspiring us to think differently about the digital systems we already have). However, in Part 1 of this series we explored a paradox. The most common uses of AI today are not loosening the grip of legacy […]

Like microservices before it, AI and agentic solutions are increasingly seen as the panacea of digital transformation. In telco circles, AI is often framed as the fastest path to escape. A way to finally move beyond the clunky, legacy worlds of OSS/BSS. Piecemeal AI projects promise quick wins, modern capabilities, and a stepping stone towards […]

The promise is simple: let AI handle the easy work, and humans focus on the hard work, the challenging work, the fun work. But the hard work is hard because it depends on intuition and experience that comes from years of guidance doing the easy work (the apprenticeship). So if AI handles all of the […]

The story of Berkshire Hathaway is a famous one. It started in textiles but Warren Buffett chose to drastically change strategy because the textiles industry was dying. You’d have to say his decision has proven to be correct. If it stayed in textiles, Buffett would almost certainly not be as famous as he is today. […]
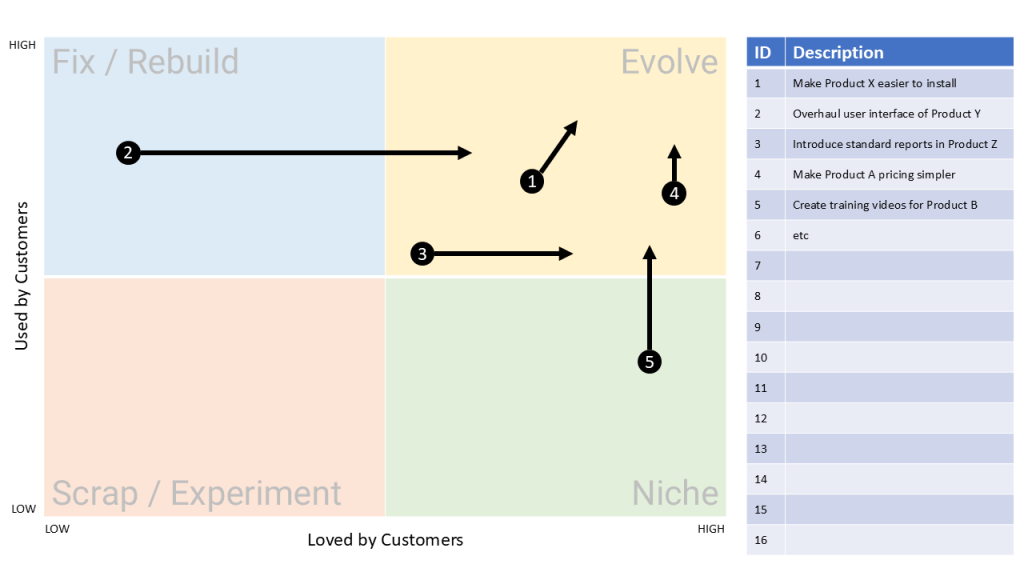
Most OSS/BSS roadmaps today overflow with novelty and buzz. You might even hear the words Agentic AI come up (not that I have anything against it but it can be a little over-hyped at times). But this series has taken a different path. We’ve looked at how to build a model that looks for enduring […]

Modern telco software roadmaps tend to be full of novel features. But what if none of that novelty is enduring? What if the silhouette of the Porsche 911 guides us on what should be included in our next OSS roadmap? The City Map From article 1 in this series, The Lindy Effect tells us that […]
When you’re planning your next-generation OSS/BSS roadmap, what’s guiding your decisions? Are you looking for and/or researching features that have never been seen before? Are you finding new problems to solve? That’s our (my) typical mindset isn’t it? What if I instead pointed you to a little-known framework that looks deep into the past to […]
You’re in the business of OSS sales (we’re all in the business of OSS sales if we want to work on an OSS project). Your OSS sales assets are full of facts, features and benefits. That fits perfectly for every buyer who thinks and says their procurement decisions are logical and calculated. Just one problem: […]
Telcos are built for resilience.But when a critical exchange burned to the ground in regional Australia, it exposed the industry’s greatest weakness and its greatest strength are one and the same: the ability to adapt. What happened to Warrnambool Exchange in 2012 wasn’t just a fire. It was a story that shattered the commonly held […]