



The Age-Old IT vs OT Debate: Who gets the Keys to Your OSS?
For decades, organisations have argued over whether IT or operations (OT) teams should control the OSS environment, as though it’s a binary decision. Giving one
The diagram below is a crass over-simplification of where the source of OSS pain (ie complexity) tends to originate from.
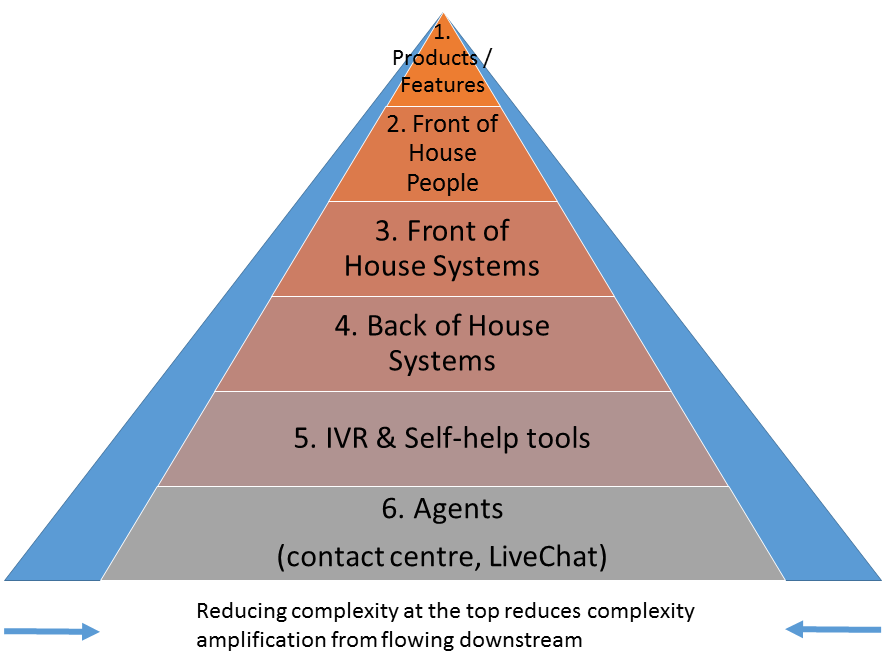
If an organisation has complexity in the upper-most layer (ie products), then this is bound to flow downstream, amplifying along the way and culminating in increased complexity at support systems like OSS/BSS.
If there are many products, with many different variants of features, bundles, offers, incentives, credits, etc, then all of these need to be supported by front of house people (eg sales), who then need systems to record their processes and details in. The greater the number of processes and systems required to support them, the greater the likelihood of fall-outs, not to mention integration effort and data grooming.
I can understand that the products / marketing department (or equivalent) needs to justify their existence by creating the momentum of newness in the marketplace. That’s what drives the revenues that indirectly fund the OSS projects that we have the opportunity to work on.
However, I suspect there is little thought into whether creating a new product that is seen as being successful (eg generating an extra $1 of ARPU compared to other existing products), actually considers the downstream costs to the organisation.
Also, to follow on from yesterday’s blog about what to focus on when selecting a new OSS, I always try to build simplification efforts into the migration planning (eg subtraction projects). Start from the top and seek simplification at every level downstream, shrinking the shoulders of the pyramid of pain.
One final thought. There are many entry points into the pyramid of pain where you could start the pain reduction process:

For decades, organisations have argued over whether IT or operations (OT) teams should control the OSS environment, as though it’s a binary decision. Giving one
Given the topical theme of the World Cup final, we’ll go with a soccer story today. For the World Cup final, do you think Argentina
For decades, scale gave large telcos purchasing power, infrastructure reach, extensive capability and millions of customers. It became one of the world’s most powerful and

Success in business, distilled to its simplest form, is often about arbitrage. The gap between supply and demand. The gap between value delivered and value