


For the World Cup Final, will You replace Messi with a Local Club Player to lower wage costs?
Given the topical theme of the World Cup final, we’ll go with a soccer story today. For the World Cup final, do you think Argentina
By now I’m sure you’ve heard about graph databases. You may’ve even read my earlier article about the benefits graph databases offer when modelling network inventory when compared with relational databases. But have you heard the Graphene Database Analogy? It can help conceptualise the migrating, cross-linking and fixing of data sets.
I equate OSS data migration and data quality improvement with graphene, which is made up of single layers of carbon atoms in hexagonal lattices (planes).
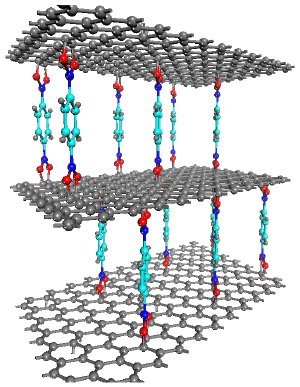
There are five concepts of interest with the graphene model:
* the example of a circuit with two related ports above might not always achieve 4 out of 4 if other checks are applied (eg if there are actually 3 ports with that associated circuit name in the data but we know it should represent a two-ended patch-lead).
Notice how closely the graphene diagram above resembles the following network layer diagram below from ITU-T Rec. G.805

I also see the graphene mindset as a potential mechanism for visualising data across layers such as:
I feel that this graphene concept is important for us to build the network inventory visualisation tools fo the future.
Or also for data proximities for root-cause (refer to this earlier post) such as:
Note: The diagram above (from graphene-info.com) shows red/blue/aqua links between graphene layers as capturing hydrogen, but is useful for approximating the concept of aligning nodes between planes


Given the topical theme of the World Cup final, we’ll go with a soccer story today. For the World Cup final, do you think Argentina
For decades, scale gave large telcos purchasing power, infrastructure reach, extensive capability and millions of customers. It became one of the world’s most powerful and

Success in business, distilled to its simplest form, is often about arbitrage. The gap between supply and demand. The gap between value delivered and value
When it comes to OSS, the term Out of the Box (or OOTB) can be correct, incorrect and highly confusing all at the same time.