Our OSS / BSS manage some of the world’s most vital comms infrastructure don’t they? That makes them pretty important assets to protect from cyber-intrusion. Therefore security is a key, but often underestimated, component of any OSS / BSS project. It can’t be an afterthought.
Let me start by saying I’m no security expert. However, I have worked with quite a few experts tasked with securing our OSS projects and picked up a few ideas along the way. We’ll share a few of those ideas in this article.
.
Let’s start by using the layers of the TMN Pyramid as a guide

Figure 1 – TMN Pyramid
.
Now we can consider how each of these pieces needs to operate securely. Security starts with how you segment and segregate your network and related systems. The aim of segmentation / segregation is to restrict malicious access to sensitive data / systems.
The diagram below shows a highly simplified three-realm design.
 :
:
Figure 2 – Simplified Security Trust Zones for OSS/BSS
Starting at the bottom:
In all likelihood, your security trust model will contain more than these three zones, but these should be the absolute minimum. There are other possibilities such as Demilitarized Zones (DMZ), Management Zones and more.
In fact, it’s quite likely that your organisation already has a trust model that you need to design your OSS/BSS stack around. This can be really challenging and time-consuming, so this is where the questions for your security / infrastructure teams need to be asked early in your OSS/BSS transformation process!
.
Once we have the security trust zones identified (whether the simplified ones indicated above, or your existing model) we now have to determine the appropriate locations for our OSS / BSS / management stack to reside.
The diagram below provides a high-level, initial sense of where things go. However, there are many considerations that could see a different architecture.
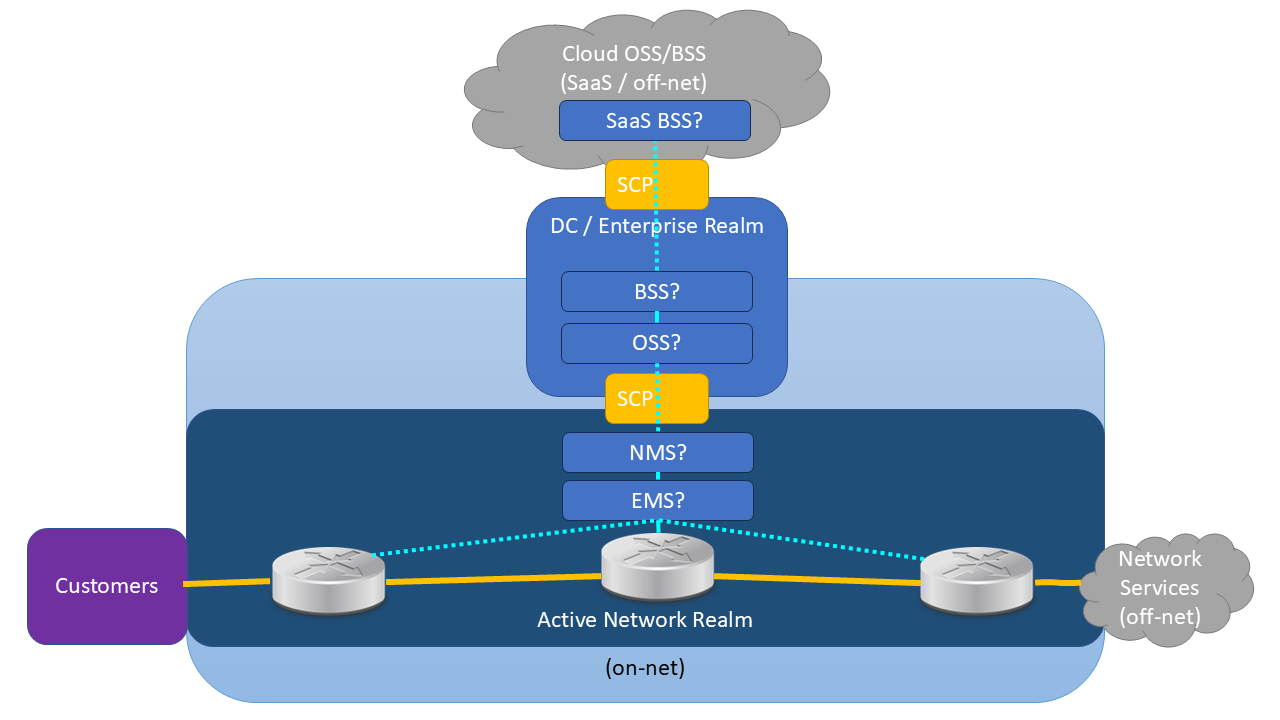
Figure 3 – Simplified Security Trust Zones with OSS/BSS Components Shown
The Active Network should be segregated from the Corporate / Enterprise network so that it can continue to provide service to customers even if the connection between them is lost (or intentionally severed if a security breach is identified). It should also be segregated so that no customers can access the EMS/NMS or corporate systems.
But this is where things get interesting. The Active Network and our Network Management stack rely on Shared Services such as DNS (Domain Naming System), NTP (Network Time Protocol), Identity / Access Management (IAM/UAM/PAM), Network Access Control (NAC), Patch Management, Anti-Virus, AD / SSO and more. These shared services tend to be housed in Corporate / Enterprise realms. If we want the Active Network to be able to operate in complete standalone mode then we need to provide special consideration to the shared services architectures.
Another important consideration is the coloured lines between components:
| Zone / Trust realm | Core operational systems (examples) | Supporting infrastructure & security tooling | Primary security objectives |
|---|---|---|---|
| Cloud OSS/BSS (off-net) | SaaS OSS modules (inventory, orchestration, assurance) Cloud BSS (CRM, billing, order management) AI/ML analytics work-loads & data lakes Remote vendor portals & licence servers | Cloud IAM & MFA API gateways / WAF CASB & DDoS scrubbing Zero-trust network access (ZTNA) brokers | Keep sensitive network data off the public Internet Encrypt all north-south API traffic Segregate tenants & environments |
| Security Control Point 1 (cloud ↔ DC) | Next-gen firewall set, IDS/IPS, reverse proxy, SSL/TLS termination, SASE Monitoring taps feeding SIEM | Inline malware sandbox Automated compliance policy engines | Enforce least-privilege flows between SaaS and on-prem Break/inspect TLS where policy permits |
| Corporate / Enterprise realm (on-net) | On-prem OSS stacks & NMS managers Ticketing, workflow, CMDB, ERP, BI Source-of-truth repositories (IPAM, GIS) Corporate AD/LDAP & RADIUS | Core DNS, NTP stratum-2 servers Mail & chat servers Patch-management & software repo Bastion / jump servers with PAM, NAC | Protect corporate and management data from the active network (but still allow key roles such as NOC to access mail and internet to perform their tasks) Authenticate & log all privileged sessions |
| Security Control Point 2 (DC ↔ Active network) | Dual-homed bastion hosts Protocol firewalls (SNMP/NETCONF/gRPC whitelists) Data diodes / one-way gateways where high assurance needed | TACACS+ / RADIUS AAA servers Central syslog collectors | Prevent lateral movement from IT to OT Rate-limit config pushes & software loads |
| Active Network realm (on-net) | Network elements (routers, switches, RAN, OLT, DWDM) EMS/element managers & SDN controllers Out-of-band DCN routers & terminal servers Stratum-1 NTP, PTP, GNSS references SCADA / environmental sensors | Local syslog / telemetry collectors Auto-rollback config vault Inline encryption for high-value links | Preserve real-time performance |
Note that we also have to consider the systems (eg user portals, asset management systems, etc, etc) that our OSS / BSS need to interface to and where they reside in the trust model.
| Aside: Traditionally, we’ve focused on perimeter defense and authenticated users are granted authorised access to a broad collection of resources. We now see the trend towards more remote users and cloud-based assets outside the enterprise-owned boundary in our OSS architectures. There’s currently debate around whether zero-trust architectures are required to segment more holistically – to restrict lateral movement within a network, assuming an attacker is already present on the network. The NIST ZTA draft discusses this emerging approach in more detail |
.
The people who interact with the various different components in the OSS/BSS stack will also impact the zone design. Here are just a few thoughts, but your specific case might be quite different:
| Persona | Zones typically accessed | Access path / tooling | Typical activities |
|---|---|---|---|
| NOC operators | Corporate / Enterprise + (indirect) Active network | OSS/NMS GUI via corporate LAN or VPN → jump server → EMS | Alarm triage, topology views, config pushes, performance troubleshooting |
| Field workforce | Corporate / Enterprise + Active network | Ruggedised laptop/tablet → LTE/NB-IoT or local console → EMS/NE | On-site fault repair, cable tracing, commissioning, access to network designs and/or alarm/ticket information |
| Network designers | Corporate / Enterprise | Inventory & planning tools, SDN simulators | Capacity design, route selection, what-if modelling |
| OSS architects | Corporate / Enterprise + Cloud | Direct corporate LAN, cloud IDE, CI/CD pipelines | Solution blueprinting, data-model governance, automation strategy |
| OSS suppliers (on-prem) | Cloud + Corporate / Enterprise + (via project VLAN) + Active Network (via management network) | Time-boxed VPN + PAM to staging & prod | Implementation, upgrade, break-fix support, patch/release management |
| OSS suppliers (SaaS) | Cloud OSS/BSS | Cloud console + API telemetry, secured by ZTNA | DevOps, road-map releases, SaaS health monitoring |
| Customers / wholesale partners | Cloud portals (DMZ) | Web/SAML portal or B2B API | Order status, self-service reporting, ticket initiation |
| Contractors / consultants | Corporate / Enterprise (limited) | Federated identity, bastion host | Requirements workshops, documentation, training |
| Security operations (SOC) | Corporate / Enterprise + All SCPs | SIEM, NDR, SOAR dashboards | Threat hunting, incident response, compliance evidence |
.
We want to uniquely control who has access to what systems and data using our OSS / BSS stack.
The Security Trust model also impacts the architectures of Identity Management (Directory Services like Active Directory), User Access Management (UAM), Privileged Access Management (PAM) and Network Access Control (NAC) solutions and how they control access to our OSS / BSS.
They serve three purposes:
Most OSS / BSS allow user authentication via Directory Services these days. Most, but not all, also allow roles / privileges to be assigned via Directory Services. For example, RBAC (Role Based Access Control) is policy that is defined by our OSS / BSS applications. It controls what functions users / groups can perform via permission management.
At a high level, we have:
This video from CyberArk provides walkthrough of how Dynamic privileged access management can provide very specific access.
For central user admi
nistration purposes, it’s ideal that the Directory Service can pass role-based information to our OSS / BSS.
.
The first step in the data security process is to identify categories of data such as unclassified, confidential, secret, etc.
We then need to consider what security mechanisms need to be applied to each category. There are four main OSS / BSS data security considerations:
.
Ensure all systems in the management stack (OSS, BSS, NMS, EMS, the network, out-of-band management, etc) are logging to a central SIEM (Security Information and Event Management) tool. Oh, and don’t do what I saw one big bank do – they had so many hits occurring just on their IPS / IDS tool that they just left it sitting in the corner unmonitored and in the too-hard basket. By having the tools, they’d ticked their compliance box, but there was no checkbox asking them to actually look at the results or respond to the incidents identified!!
This traffic is carried by the aqua links in the diagram earlier in this article.
.
Software patch management is theoretically one of the simplest security management techniques to implement. It ensures you have the latest, hopefully most secure, version of all software.
OSS / BSS / Management stacks tend to have many, many different components. Not just at the obvious application level, but operating systems, third-party software (eg runtime environments, databases, application servers, message buses, antivirus software, syslog, etc).
Patch management is often well maintained by IT teams within the Corporate / Enterprise trust zone discussed above. They have access to the Internet to download patches and tools to help push updates out. However, the Active Network zone shouldn’t have direct access to the Internet, so routine patch management could be easily overlooked and/or difficult to implement. Sometimes the software components reside on servers that are rarely logged into and patches can be easily overlooked.
The other problem is that OSS / BSS applications are often heavily customised, making it hard to follow a standard upgrade path. I’ve seen OSS / BSS that haven’t been patched for years, even with something as simple as Java runtime environments, because it causes the OSS / BSS to fail.
.
Your organisation probably already has standards and checklists in place to ensure that all of your IT assets are as secure as possible. Your OSS / BSS environments are just one of those assets. However, as the “manager of managers” of your Active Network, the OSS / BSS is probably more important to secure than most.
Your organisation might also insist that all applications, including the OSS / BSS, are built on a hardened Standard Operating Environment (SOE). However, some suppliers provide OSS / BSS as appliances, built on their own environments. These then have to go through a hardening process in alignment with your corporate IT standards.
If using a vendor-supplied off-the-shelf application, it will be quite common for it to have a default admin account on the application and database. This makes it easier for the system implementation team to navigate their way around the solution when building it. However, one of the first steps in a hardening process is to rename or disable these built-in accounts.
As “manager of managers,” your OSS / BSS’s primary purpose is to collect (or request) information from a variety of sources. Some of these sources reside in the Active Network. Others reside in the Corporate Network or elsewhere. As such, careful consideration needs to be given to what Ports / Protocols are allowed. Some systems will come pre-configured with default / open settings. However, these should be restricted to necessary protocols only, including SNMP, HTTPS, SSH, FTPS and/or similar.
Speaking of SNMP, its original design was inherently insecure as it uses a primitive method of authentication. It uses clear-text community strings to secure access to the management plane. Only version 3 of SNMP (ie SNMPv3) has the ability to authenticate and encrypt payloads, so this should be used wherever possible. Some of you may have legacy device types that precede SNMPv3 though. Alert TA17-156A provides suggestions to minimise exposure to SNMP abuse.
Also consider the environment on which you’re performing your security testing. As described in this post about OSS / BSS environments and test transitions, you’ll probably have multiple environments – PROD environments that are connected to the live Active Network devices and non-PROD environments that are connected to test lab devices and/or simulators. Where should you perform your penetration / security testing? Probably not on PROD, because you want to ensure the solution is already secure before letting it loose into Production. But you also want to ensure it’s the most PROD-like as possible. You could possibly use PRE-PROD (ie a state before a solution is cut-over to PROD), before it’s fully connected to the Active Network. Or, you could use the most PROD-like lower environment (eg Staging).
One other thing when conducting security tests and hardening – penetration testing often breaks things by injecting malicious code / data. Ensure you take a backup of any environment so you can roll-back to a working state after conducting your pen-tests.
.
In large‐scale OSS programmes the production environment is invariably the project’s critical-path anchor. Every security zone layout, firewall rule and fail-over scenario must survive architecture governance, risk review and even rounds of penetration testing. That rigour is essential for regulatory compliance, security and availability, yet it routinely adds months to the schedule. This includes lead-times for secure network zones, dual-site connectivity and security / architecture / change-board approvals that can even exceed the development effort itself. While production remains the “gold copy”, its very weight slows feedback loops and postpones value realisation.
Our projects need to be faster, so there are a lot of activities that can be done whilst the PROD environments are coming online. This is where non-PROD or pre-PROD or even sandpit environments are a strategic lever to achieving project momentum.
Non-production tiers (DEV, TEST, PRE-PROD) are used to inject velocity. Standing them up on an isolated cloud tenancy or hosted lab lets the team launch a pilot OSS stack within days rather than months. It allows the team to demonstrate early wins to sponsors (such as gather operational telemetry, designing data models, experimenting with operational processes and much more), which de-risks later design choices. These non-PROD environments are generally designed to expedite the transition of the OSS/BSS tools into the PROD environments when they become available later.
The guiding principle of non-PROD environments is to make them representative not identical. They should aim to provide as much coverage of requirements as possible, whilst also acknowledging that they can’t be a perfect replica of PROD. To be representative of PROD, we may make fast-tracking decisions such as containerised versions of the OSS, a cut-down SD-WAN core, synthetic EMS feeds, emulated/simulated lab environments and masked or generated customer data to produce behaviour close enough for functional, performance and data-migration rehearsals without exposing sensitive information. Depersonalising data satisfies ISO 27002 8.31 and GDPR obligations while avoiding the lengthy approvals associated with live datasets.
Because this pilot realm is air-gapped – physically or via one-way gateways – much of the heavy security stack (pen-tests, PAM vaults, SIEM connectors) can be deferred. At most, a minimal perimeter of jump hosts, role-based access control and pipeline-driven image signing is usually sufficient. We may even decide whether to connect to existing physical / virtual lab environments or generate them separately to remain entirely air-gapped for the Pilot Phase of the OSS/BSS transformation.
That minimalist posture is deliberate: every unnecessary control weakens the “speed premium” these sandboxes are meant to deliver.
Finally, a disciplined promote-path turns non-PROD momentum into PROD -ready artefacts. Infrastructure-as-Code templates, configuration baselines and automated test suites authored in DEV advance unchanged through TEST and PRE-PROD, accumulating security hardening and audit evidence at each stage. When the production platform eventually arrives, the OSS payload is already proven – installation becomes an execution step rather than an exploration exercise, trimming weeks from cut-over and sharply reducing rollback risk.
To design your Pilot Environment, you may like to go back to Figure 3 above and determine what components you need to include / exclude / simulate and in what trust model.
.
As the OSS delivery team is generally dependent upon their organisation’s security and infrastructure teams for stand-up of PROD (and even non-PROD) environments, the following list of questions might help you to identify key requirements for building your Pilot environment and getting it ready for an OSS/BSS/NMS/NE build.
.
The following is a list of security standards that I’ve used in the past:
As I mentioned at the start, I’m far from being an expert in the field of network or data security. I’d love to get your feedback if I’m missing anything important!!