“Data governance constructs a strategy and a framework through which an organization (company as well as a state…) can recognize the value of its data assets (towards its own or global goals), implement a data management system that can best leverage it whilst putting in place controls, policies and standards that simultaneously protect data (regulation & laws), ensure its quality and consistency, and make it readily available to those who need it.”
TM Forum Data Governance Team.
I just noticed an article on TM Forum’s Inform Platform today entitled, “Telecoms needs a standardized, agile data governance framework,” by Dawn Bushaus.
The Forum will publish a white paper on data governance later this month. It has been authored with participation from a huge number of companies including Antel Uruguay, ATC IP, BolgiaTen, Deloitte, Ernst & Young, Etisalat UAE, Fujitsu, Globe Telecom, Huawei Technologies, International Free and Open Source Solutions Foundation, International Software Techniques, KCOM Group, Liquid Telecom, Netcracker Technology, Nokia, Oracle, Orange, Orange Espagne, PT XL Axiata, Rogers Communications, stc, Tech Mahindra, Tecnotree, Telefonica Moviles, Telkom and Viettel. Wow! What a list of luminaries!! Can’t wait to read what’s in it. I’m sure I’ll need to re-visit this article after taking a look at the white paper.
It reminded me that I’ve been intending to write an article about data governance for way too long! We have many data quality improvement articles, but we haven’t outlined the steps to build a data governance policy.
One of my earliest forays into OSS was for a brand new carrier with a brand new network. No brownfields challenges (but plenty of greenfields challenges!!). I started as a network SME, but was later handed responsibility for the data migration project. Would’ve been really handy to have had a TM Forum data governance guide back then! But on the plus side, I had the chance to try, fail and refine, learning so much along the way.
Not least of those learnings was that every single other member on our team was dependent on the data I was injecting into various databases (data-mig, pre-prod, prod). From trainers, to testers, to business analysts, to developers and SMEs. Every person was being held up waiting for me to model and load data from a raft of different network types and topologies, some of which were still evolving as we were doing the migration. Data was the glue that held all the other disciplines together.
We were working with a tool that was very hierarchical in its data model. That meant that our data governance and migration plan was also quite hierarchical. But that suited the database (a relational DB from Oracle) and the network models (SDH, ATM, etc) available at that time, which were also quite hierarchical in nature.
When I mentioned “try, fail and refine” above, boy did I follow that sequence… a lot!! Like the time when I was modelling ATM switches that were capable of a VPI range of 0 to 255 and a VCI range of 0 to 65,535. I created a template that saw every physical port have 255 VPIs and each VPI have 65,535 VCIs. By the time I template-loaded this port-tree for each device in the network overnight, I’d jammed a gazillion unnecessary records into the ports table. Needless to say, any query on the ports table wasn’t overly performant after that data load. The table had to be truncated and re-built more sensibly!!
But I digress. This is a how-to guide, not a how-not-to. Here are a few hints to building a data governance strategy:
- Start with a WBS or mind-map to start formalising what your data project needs to achieve and for whom. This WBS will also help form the basis of your data migration strategy
- Agile wasn’t in widespread use back when I first started (by that I mean that I wasn’t aware of it in 2000). However, the Agile project methodology is brilliantly suited to data migration projects. It’s also well suited to aligning with WBS in that both methods break down large, complex projects into a hierarchy of bite-sized chunks
- I take an MVD (Minimum Viable Data) approach wherever possible, not necessarily because it’s expensive to store data these days, but because the life-cycle management of the data can be. And yet the extra data points are just a distraction if they’re never being used
- Data Governance Frameworks should cover:
- Data Strategy (objectives, org structure / sponsors / owners / stewardship, knowledge transfer, metrics, standards / compliance, policies, etc)
- Regulatory Regime (eg privacy, sovereignty, security, etc) in the jurisdiction/s you’re operating in or even just internal expectation benchmarks
- Data Quality Improvement Mechanisms (ensuring consistency, synchronised, availability, accuracy, usability, security)
- Data Retention (may overlap with regulatory requirements as well as internal policies)
- Data Models (aka Master Data Management – particularly if consolidating and unifying data sources)
- Data Migration (where “migration” incorporates collection, creation, testing, ingestion, ingestion / reconciliation / discovery pipelines, etc)
- Test Data (to ensure suitable test data can underpin testing, especially if automated testing is being used, such as to support CI/CD)
- Data Operations (ongoing life-cycle management of the data)
- Data Infrastructure (eg storage, collection networks, access mechanisms)
- Seek to “discover” data from the network where possible, but note there will be some instances where the network is master (eg current alarm state), yet other instances where the network is updated from an external system (eg network design being created in design tools and network configs are then pushed into the network)
- There tend to be vastly different data flows and therefore data strategies for the different workflow types (ie assurance, fulfilment / charging / billing, inventory / resources) so consider your desired process flows
- Break down migration / integration into chunks, such as by domain, service type, device types, etc to suit regular small iterations to the data rather than big-bang releases
- I’ve always found that you build up your data in much the same way as you build up your network:
- Planning Phase:
- You start by figuring out what services you’ll be offering, which gives an initial idea about your service model, and the customers you’ll be offering them to
- That helps to define the type of network, equipment and topologies that will carry those services
- That also helps guide you on the naming conventions you’ll need to create for all the physical, logical and virtual components that will make up your network. There are many different approaches to naming conventions, but I always tend to start with ITU as a naming convention guide (click here for a link to our naming convention tool)
- It’s important to know how the different network domains connect together and how these can be stitched together using linking keys. For example, let’s say we have a router (IP domain) that connects to a fibre cable (physical network domain) via an optical patchlead. The router and its ports can be polled via an API because it’s active equipment. The fibre cable, although passive, can be recorded in a Physical Network Inventory (PNI) solution, which will also have an API. However, the patchleads are not always recorded in any system, but provides the link between PNI and IP domain data sets. There are a variety of approaches that can be used but we won’t cover them all in this article. Root Cause and Service Impact Analysis (RCA / SIA) rely on this east to west and top to bottom stitching of network and service data
- But these are all just initial concepts for now. The next step, just like for the network engineers, is to build a small Proof of Concept (ie a small sub-set of the network / services / customers) and start trialling possible data models and namings
- Migration Strategy (eg list of environments, data model definition, data sources / flows, create / convert / cleanse / migration, load sequences with particular attention to cutover windows, test / verification of data sets, risks, dependencies, etc)
- Implementation Phase – Build the data up in layers, in the same sequence as building the actual network (more-or-less)
- Reference Data (eg service types, equipment types / makes / models, bandwidth / speeds, connector types, device templates, etc, etc)
- Location Data (eg Countries / Sites / Buildings / Rooms / Racks)
- “Nodal” Data (eg this could be a hierarchy of data within the Nodes / Equipment – depending on the granularity of your data, this could be at system, device, card/port, or serial number level of detail). This could also include logical / virtual resources (eg VNFs, apps, logical ports, VRFs, etc)
- Map / geo-location of physical infrastructure (ie associate nodes with locations)
- Containment (ie easements, ducts, trays, catenary wires, towers, poles, etc that “contain” physical connections like cables)
- Physical Connectivity (cables, joints, patch-leads, radio links, etc – ideally port-to-port connectivity, but depends on the granularity of the equipment data you have)
- Intra-Domain Logical Connectivity (eg trails, VPNs, IP address assignments, etc, generally from within a single source such as an EMS or NMS)
- Inter-Domain Connectivity (to establish connectivity that crosses domains, eg IP, transport, RAN, patch-leads, cables, etc may require associations to be established between physical and logical data, generally from disparate data sources)
- Discovery – Build collectors and discovery processing engines that collect data from various sources (especially the network / NE / NMS / EMS) and automate stitching and reconciliation of nodal, intra-domain and cross-domain data sets (see “stitching” example above), generally in the following sequence:
- Nodal (including equipment hierarchy models)
- Intra-domain connectivity
- Inter-domain connectivity (typically the hardest to stitch together due to data coming from disparate sources)
- Other cross-linked data sets (eg IPAM to inventory, etc)
- Customer Data
- Service Data (and SLA data)
- Power Networks / Feeds (can be like a combination of Nodal and Physical connectivity data, noting that power can be the root-cause of over 50% of failures in some networks but is often overlooked in data builds)
- Telemetry (ie the networks that help collect network health data for use by OSS)
- Other data source collection such as security, environmentals, etc
- Supplementary Info (eg attachments such as photos, user-guides, knowledge-bases, etc, hyperlinks to/from other sources, etc)
- Build Integrations / Configurations / Enrichments in OSS/BSS tools and or ingestion pipelines
- Implement and refine data aging / archiving automations (in-line with retention policies mentioned above)
- Policies: Establish data governance and ownership rules (eg user/group policies)
- Implement and refine data privacy / masking automations (in-line with privacy policies mentioned above)
- Build closed-loop reconciliation processes that reinforce continual data improvement (eg Data Operations Centres (DOC)) rather than the typical data death spiral
- Operations Phase
- Ongoing ingestion / discovery (of assurance, fulfilment, inventory / resource data sets)
- Continual improvement processes to avoid a data quality death spiral, especially for objects that don’t have a programmatic interface (eg passive assets like cables, pits, poles, etc). See big loop, little loop and synchronicity approaches. There are also many other data integrity posts on our blog.
- Build and refine your rules engines, analytics and/or Agentic AI solutions (see post, “Step-by-step guide to build a systematic root-cause analysis (RCA) pipeline“)
- Build and refine your decision / insights engines and associated rules (eg dashboards / scorecards, analytics tools, notifications, business intelligence reports, scheduled and ad-hoc reporting for indicators such as churn prediction, revenue leakage, customer experience, operational efficiencies, etc)
- In addition to using reconciliation techniques to continually improve data quality, also continually verify compliance for regulatory regimes such as GDPR
- Ongoing refinement of change management practices (especially the DOC mentioned above)
Click here or on the image below to download an infographic version:
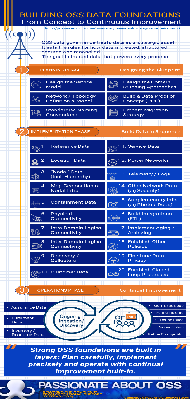
I look forward to seeing the TM Forum report when it’s released later this month, but I also look forward to hearing suggested adds / moves / changes to this OSS / BSS data governance article from you in the meantime.
If you need any help generating your own data governance framework, please contact us.




