


For the World Cup Final, will You replace Messi with a Local Club Player to lower wage costs?
Given the topical theme of the World Cup final, we’ll go with a soccer story today. For the World Cup final, do you think Argentina
We are currently living through a revolution for the OSS/BSS industry and the customers that we serve.
It’s not a question of if we need to innovate, but by how much and in what ways.
Change is surrounding us and impacting us in profound ways, triggered by new technologies, business models, design & delivery techniques, customer expectations and so much more.
Our why, the fundamental reasons for OSS and BSS to exist, is relatively unchanged in decades. We’ve advanced so far, yet we are a long way from perfecting the tools and techniques required to operationalise service provider networks.
Imagine a future OSS where:
This call for innovation, whilst having no reward like the XPRIZE (yet), seeks out the best that we have to offer and the indicators for what OSS can be into the future. It provides existing indicators to the future but seeks your input on what else is possible.
Innovation is not just a better product or technology. It’s a complex mix of necessity, evangelism, timing, distribution, exploration, marketing and much more. It’s not just about thinking big. In many cases, it’s about thinking small – taking one small obstacle and re-framing, tackling the problem differently than anyone else has previously.
We issue this Call for Innovation as a means of seeking out and amplifying the technologies, people, companies and processes that will transform, disrupt and, more importantly, improve the parallel worlds of OSS and BSS. Innovation represents the path to greater enthusiasm and greater investment in our OSS/BSS projects.
In this article we’ll look at:
At the highest level, the use cases for OSS and BSS have barely changed since the earliest tools were developed.
We still want to:
The problem statements we face still relate to doing all these use-cases, only cheaper, faster, better and more precisely.
Let’s take those use-cases to an even higher level and pose the question about customer interactions with our OSS:
Actual customer experiences in relation to the questions above today might be 1) Confusing, 2) Arduous, 3) Uniquely challenging and 4) Unintuitive.
The challenge is to break these down and reconstruct them so that they’re 1) Easy to follow, 2) Simple, 3) Less bespoke and 4) Navigable by novices.
Despite the best efforts of so many brilliant specialists, a subtle sense of disillusionment exists when some people discuss OSS/BSS solutions, to the point that some consider the name OSS, the brand of OSS, to be tarnished. Whilst there are many reasons for this pervasive disappointment, the real root-causes are arguably the big (big projects, budgets, teams, complexity and expectations) and the small (ambition, improvement / thinking, experimentation and tolerance of failure).
We have contributed to our own complexity and had complexity thrust upon us from external sources. The layers of complexity entangle us. This entanglement forces us into ongoing cycles of incremental change. Unfortunately, incremental change is impeding us from reaching for a vastly better future.
2.2 The 80/20 rule of OSS in a fragmented market
The diagram below shows Pareto’s 80/20 rule in the form of a telco functionality long-tail diagram:

True to Pareto’s Principle, this chart indicates that 80% of value is delivered by 20% of functionality (red-shaded rectangle). Meanwhile 20% of value is delivered by the remaining 80% of functionality (blue arrow).
If we take one sector of the OSS market – network inventory – there are well over 50 products / vendors servicing this market.
The functionalities in the red shading are the non-negotiables because they’re the most important. All 50+ products will have these functionalities and have had them since their Minimum Viable Product first came onto the market. It also means 50+ sets of effort have been duplicated and 50+ competitors fighting for the same pool of customers. It also means there are 50+ vendors for a buyer to consider when choosing their next product (often leading to analysis paralysis).
But rather than innovating, trying to improve the functionality that “moves the needle” for buyers (ie the red shading), instead most vendors attempt to innovate in the long tail (ie the blue arrow).
Of course innovation is needed in the blue arrow, but innovation and consolidation is more desperately needed in the red shaded-box (see this article for more detail).
Exponential technologies are landing all around us from adjacent industries. With them, it becomes a question about how to remove the constraints of current OSS and unleash them.
We’ve all heard of Moore’s Law, which predicts the semiconductor industry’s ability to exponentially increase transistor density in an integrated circuit. “Moore’s prediction proved accurate for several decades, and has been used in the semiconductor industry to guide long-term planning and to set targets for research and development. Advancements in digital electronics are strongly linked to Moore’s law: quality-adjusted microprocessor prices, memory capacity, sensors and even the number and size of pixels in digital cameras… Moore’s law describes a driving force of technological and social change, productivity, and economic growth.”
Moore’s Law is starting to break down, but it’s exponentiality has also proven to be helpful for long-term planning in many industries that rely on electronics / computing. That includes the communications industry. By nature, we tend to think in linear terms. Exponentiality is harder for us to comprehend (as shown with the old anecdote about the number of grains of wheat on a chessboard).
The problem, as described in a great article on SingularityHub, is that the exponentiality of technological progress tends to surprise us as change initially creeps up on us quietly, then overwhelms us in situations like this:
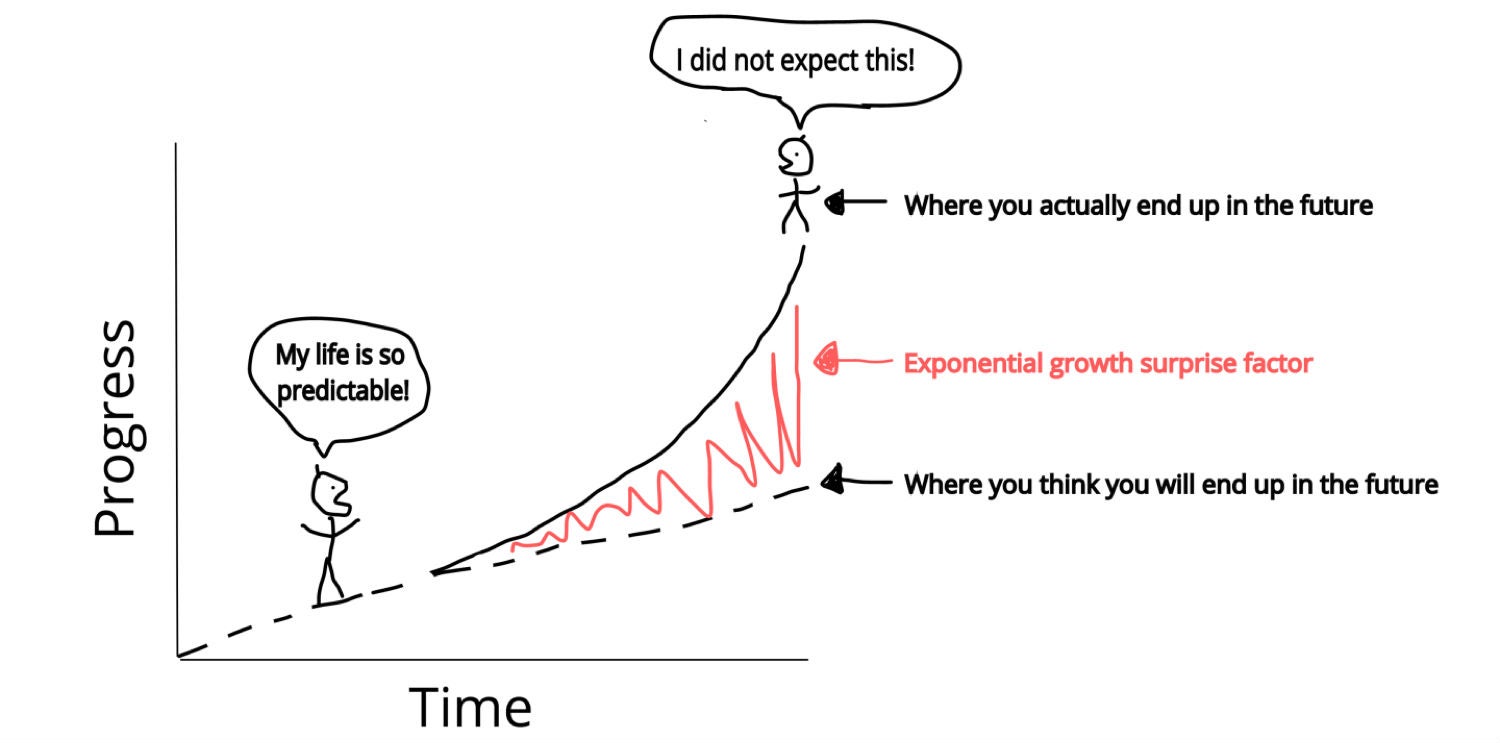
(source: Singularity Hub)
Hardware is scaling exponentially, yet our software is lagging and wetware (ie our thinking) could be said to be trailing even further behind. The level of complexity that has hit OSS in the last decade has been profound and has largely overwhelmed the linear thinking models we’ve applied to OSS. The continued growth from technologies such as network virtualisation, Internet of Things, etc is going to lead to a touchpoint explosion that will make the next few years even more difficult for our current OSS models (especially for the many tools that exist today that have evolved from decade-old frameworks).
Countering exponential growth requires exponential thinking, as described in this article on WIRED. We know we’re going to deal with vastly greater touch-points and vastly greater variants and vastly greater complexity (see more in the triple-constraint of OSS). Too many OSS projects are already buckling under the weight of this complexity.
So where to start?
A journey of enlightenment is required. Arguably this type of transformation is required before an digital transformation can proceed. This starts by asking questions that challenge our beliefs about OSS and the customers + markets they serve. This link poses 22 re-framing questions that might help you on a journey to test your own beliefs, but don’t stop at those seed questions.
The following forces are driving future changes, both positive and negative, for the OSS industry and the customers it serves:
Before considering what the future might look like, we must acknowledge that nobody can predict the future. There are simply too many variables at play. The best we can do is propose possible future scenarios such as:
From these scenarios, we can make decisions on how to best steer OSS innovation. <WIP link>
The topics related to this Call for Innovation can be wide and varied (the big), yet sharp in focus (the small). They can relate directly to OSS technologies or innovative methods brought to OSS from adjacent fields but ultimately they’ll improve our lot. Not just change for the sake of the next cool tech, but change for the sake of improving the experience of anyone interacting with an OSS.
The following is just a small list of starting points where exponential improvements await:
The digital experiences we rely on today are evolving. The third generation of the Internet (Web 3.0) is on the horizon, with many of its necessary elements already taking shape (eg blockchain / crypto-currencies, digital proof-of-ownership, virtual worlds, etc). It will essentially be a more immersive, secure, private, user-friendly and de-centralised version of the Internet we know today.
Trust will be a fundamental element of society’s up-take of web3 technologies. Access to these experiences will occur via the on-ramp of communications networks. Being regulated in their local jurisdictions, telcos have an opportunity to act in the role of privacy, security and consumer protection stewards for everyone entering the world of Web3. Leveraging the long-held position of trust that telcos have with their business and residential customers, OSS/BSS have the opportunity to deliver trust mechanisms for Web3.
Whether, and how, we tap into this opportunity remains to be seen.
Many people talk about the possibility of a zero-touch future OSS. I don’t foresee that, but do see a future of lower-touch, smarter-touch, different touch. The entire way we will interact with our OSS will change fundamentally – from dealing with our two-dimensional device screens (eg PCs, phones and tablets) to future devices that allow us to have enriched experiences in three dimensions – in reality and with augmented realities.
Capacity Planner – The CAD designs of the past were necessary because field workers needed printed design packs that showed network changes. Field workers needed to translate these drawings and designs into the 3 dimensional worlds they experienced. Since capacity planners perform designs remotely, they make design decisions with incomplete awareness of site (eg site furniture, etc). In the future (and today), designers will have 3D photogrammetric models of site and can perform adds/moves/changes directly onto the model. Most of these designs will be generated automatically based on cost-benefit analysis. However, a human may be required to perform a quality audit of the design or generate any bespoke designs that aren’t catered for by the auto-designer. For example, certain infrastructure changes may be required before being able to drag a new device type (make and model) onto the 3D model and include other relevant annotations.
Field Worker – Field workers are already using mobility devices to aid the efficiency of work on site. This will change further when field workers use augmented reality headsets to see network change designs as overlays whilst they’re working. They will see the new device location marked on the tower (as described above) and know exactly which piece of equipment needs to be installed where. Connection details will also be shown and image processing on the head-set will identified whether connectors have been wrongly connected. Even installation guides will appear via the heads-up display of AR to aid techs will the build.
Similarly, a fibre splice technician will be guided which strand / tube fibre to splice to which other strand / tube as image processing will identify cables and colours and match them up with designs. Where there are any discrepancies between field records and inventory records, these will be reconciled immediately without the need for returning red-line markup as-built drawings to be transcribed into the OSS.
Perhaps most important is the automation that keeps passive infrastructure reconciled whilst field techs perform their daily activities. We all know that data quality deteriorates as it ages. Since passive infrastructure (racks, cables, patch panels, splice boxes, etc) is unable to send digital notifications, their data tends to be updated only through design drawings, which are rarely touched. However, field workers “see” this infrastructure whilst they’re on site. As field workers will now upload imagery of the site they’re working on (as photos or AR streams), image processing will automatically identify QR / barcode / RFID tags to identify where assets are in space and time, thus providing a “ping” on the data to refresh it and reconcile its data accuracy. Entire asset life-cycles are better tracked and correlated with who was on site when life-cycle statuses changed (eg adds / moves / changes in location or configuration).
Data Centre Repair Technician – Since most infrastructure in a data centre will be standardised, commoditised and virtualised, the primary tasks will be replacing failed hardware and performing patching. DC Techs will do a daily fix-run where their augmented reality devices will show which rack and shelf contain faulty equipment that needs to be replaced. Image processing will even identify whether the correct device or card is being installed in place of the failed unit. AR headsets will also guide DC techs on patching / re-patching, ensuring the correct connectivity is enabled.
NOC (and/or WOC and SOC) operator – As with today, a NOC operator will monitor, diagnose and coordinate a fix. However, with AIOps tools automatically identifying and responding to all previously identified network health patterns, the NOC operator will only handle the rare event patterns that haven’t been previously codified. For these rare cases, the NOC operator will have an advanced diagnosis solution and user interface, where all network domain data and available data streams (events, telemetry, logs, changes, etc) can be visualised on a single palette. These temporal/spatial data streams can be dragged onto the UI to aid with diagnosis, although the AIOps will initially present the data streams on the palette that contain likely anomalies (rather than the hundreds of unassociated metric graphs that will be available from the network). The UI to support the rare cases will look fundamentally different to the UI that supports bulk processing today (eg alarm lists and tickets).
Command and control (C&C) – Since the AIOps and SON handles most situations automatically (eg auto-fix, self-optimise, auto-ticket), only rare situations require command and control mechanisms by the NOC team. However, these C&C situations are likely to be invoked during crisis, high severity and/or complex resolution scenarios. Rather than handling these scenarios by tick(et) and flick, the C&C tool will provide collaborative control of resources (people and technology) using sophisticated decision support. The C&C solution will be tightly coupled with business continuity plans (BCP) to drive pre-planned, coordinated responses. They will be designed to ensure BCPs are regularly tested and refined.
System Administrators – These teams will arguably become the most important people for which OSS user interfaces (UIs) will be designed. These users will design, train, maintain and monitor the automations of future OSS. They will be responsible for keeping systems running, setting up product catalogs, designing workflows such as orchestration plans, identifying AIOps event patterns and response workflows, etc. They will be responsible for system configurations and data migrations to ensure the workflows for all other personas are seamless, immersive and intuitive. Whereas other persona UIs will be highly visual in nature, the dedicated UIs of system administrators are likely to look like the OSS UIs that we’re familiar with today (eg lists / logs, BPMN workflows, configs, technical attributes, network connectivity / topology maps, etc)
Product Designers – The product team will be provided with a visual product builder solution, where they can easily compose new offerings, contracts, options/variants, APIs, etc from atomic objects already available to them in the product catalog. Product Designers become the Lego builders of telco, limited only by their imaginations.
Marketing – The marketing team will be provided with sophisticated analytics that leverages OSS/BSS data to automatically identify campaign opportunities (eg subscribers that are churn risks, subscribers that are up-sell targets, prospects that aren’t subscribers but are within a designated coverage area such as within 100m of a passing cable, etc)
Sales Teams – Most sales will occur via seamless self-service mechanisms (eg portals, apps, etc). Some may even occur via bundled applications (where third-parties have utilised a carrier’s Network as a Service APIs to autogenerate telco services to be bundled with their own service offerings). Salespeople will only work with customers for rarer cases, but will use a visual quote and service design builder to collaborate with customers. Sales teams will even be able to walk clients through reality twins of service designs, such as showing where their infrastructure will reside in racks (in a DC) on towers, etc.
We don’t claim to be able to predict the future. Many of the examples described above are already available in their nascent forms or provide a line-of-sight to these future scenarios. It’s quite likely that we’ve overlooked key initiatives, technologies and/or innovations. We’d love to hear your thoughts. What have we missed or misrepresented? Are you working on any innovations or products that you’d love to tell the world all about? Leave us a comment in the comment box below to share your predictions.

Given the topical theme of the World Cup final, we’ll go with a soccer story today. For the World Cup final, do you think Argentina
For decades, scale gave large telcos purchasing power, infrastructure reach, extensive capability and millions of customers. It became one of the world’s most powerful and

Success in business, distilled to its simplest form, is often about arbitrage. The gap between supply and demand. The gap between value delivered and value
When it comes to OSS, the term Out of the Box (or OOTB) can be correct, incorrect and highly confusing all at the same time.