


The Age-Old IT vs OT Debate: Who gets the Keys to Your OSS?
For decades, organisations have argued over whether IT or operations (OT) teams should control the OSS environment, as though it’s a binary decision. Giving one
Most OSS programs stall before they even start, waiting on the longest pole in the tent – production infrastructure – to become available for the first OSS software builds. This invariably involves waiting on solution designs, procurement, approvals, integrations and more. But what if there were a faster way?
There’s one step that we use on almost all transformations, one that’s too often overlooked, yet gives delivery teams a running start. While everyone else is bogged down in lengthy design activities, governance checklists, change approvals, security team sign-offs and more, speed-focused projects use this technique to build, test, integrate and train before PROD even exists, shaving months off delivery timelines.
It’s not just a workaround. It’s a strategic accelerator!
As we discussed in an earlier article, we often need to think laterally, to slice and dice the work breakdown in different ways, to eliminate lengthy dependencies wherever possible. And waiting on PROD infrastructure, which can often take well over a year, is one of those lengthy dependencies.
Many OSS vendors still aim to deliver per the diagram below, which is very “waterfall” in nature, where there’s a heavy dependency on the Design & Procure phase early in the project.
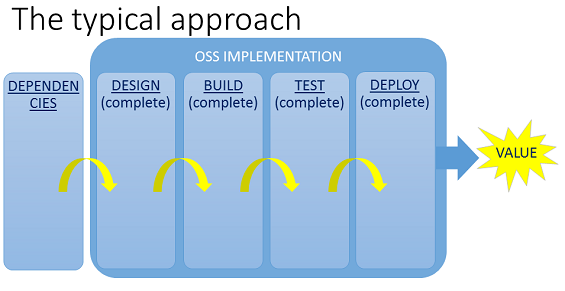
Figure 1 – Traditional OSS Transformation Stages
The alternate approach that we prescribe to seeks to deliver in multiple phases that deliver business value (more on that later), not artefacts or waterfall stages. It just requires some lateral thinking into what constitutes value to the business.

Figure 2 – An alternate OSS Transformation Approach that Seeks Early Delivery of Value
In OSS transformation projects, it’s common to wait until production infrastructure is designed, ordered and provisioned before starting meaningful OSS build activities (as per figure 1). But that’s often a costly mistake in terms of both momentum and risk, not to mention budget burn-down.
Instead, a pilot OSS build, delivered in a lab or non-PROD environment, can be a critical enabler of acceleration, alignment and de-risking (as per Figure 2 and then elaborated on in Figure 3 below).

.
Looking closely at Figure 3, one of the most practical reasons to build a pilot OSS environment early is time – more specifically, speeding up the time to value.
T1 (pilot environment build time) is typically far shorter than T2 (production environment build time).
Why? Because pilot environments can be air-gapped, standalone and provisioned on lower-spec infrastructure. These non-PROD environments don’t require the same rigorous approvals that PROD environments do in relation to:
Security and privacy designs and approvals
High availability configurations
Full integration with change-managed systems like production networks and other systems like OSS/BSS
Regulatory or compliance sign-offs
This means you can start building, testing, and demonstrating value (t1) long before your production cloud or data centre environment is even available (t2).
Depending on the environment rules within your organisation, t1 could be as little as days (eg if an off-the-shelf OSS application is installed on an existing server, on existing hosting or even on a stakeholder’s PC/laptop). By comparison, t2 can often take 18 months to 2 years, especially if approvals are dependent upon detailed designs being completed first.
.
Waiting for production infrastructure readiness is what we call “the dead zone.” It introduces dead time, and in large OSS projects, dead time kills momentum.
As represented by the various diamonds in Figure 3, lab or pilot environment enables a wide range of parallel activities that deliver real value to the business:
Application builds and functional walkthroughs
Initial data export, cleanse and augmentation before initial data import
Integration with real or simulated BSS/EMS/NMS/network platforms in network lab environments
Execution of test cases, FAT (Factory Acceptance Testing), DMT (Data Migration Testing) and preliminary SIT (system integration testing, which can also facilitate workflow / dataflow analysis and refinement)
Initial training of internal teams to aid them with product familiarity to assist with the transformation activities that follow. These environments are also an important part of doing the immersive “apprenticeship” learnings on these systems as they’re being built rather than lab-based training when the project is nearing completion
These early wins help align stakeholders, demonstrate tangible progress, experiment and create opportunities for feedback and iteration outside the stresses of working on production environments. One of the important rules of complex change is to involve impacted stakeholders in the change process, not just giving them a week of training at the end of the project and forcing them to accept the change immediately upon handover.
.
The OSS Pilot/Lab phase provides a sandbox where integrations can be tackled early with fewer consequences for failure. Even if the lab isn’t production-grade, it can connect to:
A simulated or emulated Lab Network
Mock or cloned interfaces to upstream/downstream systems (e.g., CRM, billing, NMS)
Subsets of data (often cleansed or anonymised) from existing PROD
This means critical integration points can be validated and automated ahead of go-live, reducing the risk of late-stage surprises.
As shown in Figure 3, data from the current PROD platform is extracted and cleansed / augmented incrementally during data extract-transform-load (ETL) sequences #2.1 to 2.n. This progressively feeds the pilot environment to ensure realism without the overhead of full PROD integration at day one (as per go-live).
OSS transformations are rarely conducted in isolation. There are usually many other changes going on around them. Having early access to a platform to conduct preliminary SIT (system integration testing) not only helps the OSS Transformation, but also aids the other in-flight projects that either have dependencies on the OSS platform and/or that the OSS platform is dependent on.
.
By the time the Pre-PROD and final PROD environments are built (T2), the team has already:
Validated the application build process
Tested core functionality
Identified data quality, process and/or OSS application issues
Built out deployment and integration automation
Delivered user training and support materials
Defined process and integration dependencies (and often even refined them)
This makes the final transition smoother, more predictable and ultimately faster.
We can clearly see that if we were to use the traditional approach of waiting for PROD infrastructure (as per Figure 1), it’s quite feasible for millions of dollars of the project budget will have been spent in the first 18-24 months of the project before delivering any value to the business units / stakeholders.
By comparison, the stars in Figure 2 and the diamonds in Figure 3 represent tangible value and proof of progress, which should reduce fear relating to budget burndown by the time PROD infrastructure is ready after t2 in Figure 3.
.
Any OSS transformation requires a range of different test phases. Figure 3 shows a progressive build strategy, where the lab forms the initial base, and value is layered gradually through Builds 1 and 2, DMT rounds, integration testing, and eventually Pre-PROD and UAT (User Acceptance Testing). This de-risks production deployment, because issues are caught earlier, when they’re cheaper and easier to resolve.
The progressive layering-in and testing of data should also assist with the often-challenging step of reconciling in-flight data sets when migrating from the Current PROD environment to the New PROD environment during the cutover window.
.
When it comes to performing an OSS Transformation for our clients, we often break it down into the following steps in Figure 4 below:
But the Sandpit / POC / Pilot phase is a vital stepping stone to transition between the two main phases above. Often Phase 1 can be all about documentation and “Telling” without demonstrating any real proof of viability. For example, if doing a vendor selection process, just stopping at the completion of an RFI / RFP leaves a lot of unknowns or “what ifs?” in the minds of key stakeholders.
Instead, we prefer to use the Sandpit / POC / Pilot as a way of “Showing” and delivering a platform that helps with planning and transitioning into the implementation phase. The proof is more tangible if you actually have a working platform that your stakeholders can interact with.
.
![]()
Figure 4. High-Level Transformation Plan
.
A pilot OSS build isn’t a detour from the real work to choose a best-fit vendor solution. It is the real work, just in a safer and faster environment. It enables the team to align, test, learn, experiment and refine while waiting for the more complex and time-consuming production infrastructure to become available. In large-scale and complex OSS programs, we can’t reiterate enough how we routinely use this approach is a critical OSS Transformation insurance mechanism.

For decades, organisations have argued over whether IT or operations (OT) teams should control the OSS environment, as though it’s a binary decision. Giving one
Given the topical theme of the World Cup final, we’ll go with a soccer story today. For the World Cup final, do you think Argentina
For decades, scale gave large telcos purchasing power, infrastructure reach, extensive capability and millions of customers. It became one of the world’s most powerful and

Success in business, distilled to its simplest form, is often about arbitrage. The gap between supply and demand. The gap between value delivered and value