Since OSS were first built, they’ve been designed around the belief that more complete information creates better operations. That belief made sense when they were designed by Engineers for Engineers. When network, service, customer, inventory, topology and assurance data was scarce, fragmented and hard to access. The organisation with the best information usually had the […]

Phone books now look like a relic from another era. Stone. Cold. Dead. But they were once one of the most powerful business growth engines in the world. Owned by telcos! As they declined in importance, Telcos didn’t just lose a directory. They totally forgot they were matchmakers. Phone books were never just paper directories. […]

The old proverb above really resonates. I love this industry. You could even say I’m Passionate About OSS. And like many of us, I’ve been a beneficiary of trees that other people planted – frameworks, knowledge, standards, examples, terminology, APIs, architectures and shared wisdom. But it feels like we’re now on the cusp of generational […]

Every carrier knows it needs a clear product catalogue, with well-defined service and resource definitions. But it is not always obvious where to start. Across the world, most carriers sell broadly similar families of products, whether broadband, mobile, voice, VPN or bundles. At the same time, every operator needs to differentiate, which means no two […]
I have a really important question for you to ask yourself today. It’s a question that shapes a lot of our thinking about how I can help the OSS/BSS/telco industry. How does what I do make more money for clients? Not just what your company does. Not what your brand says on the website. Not […]
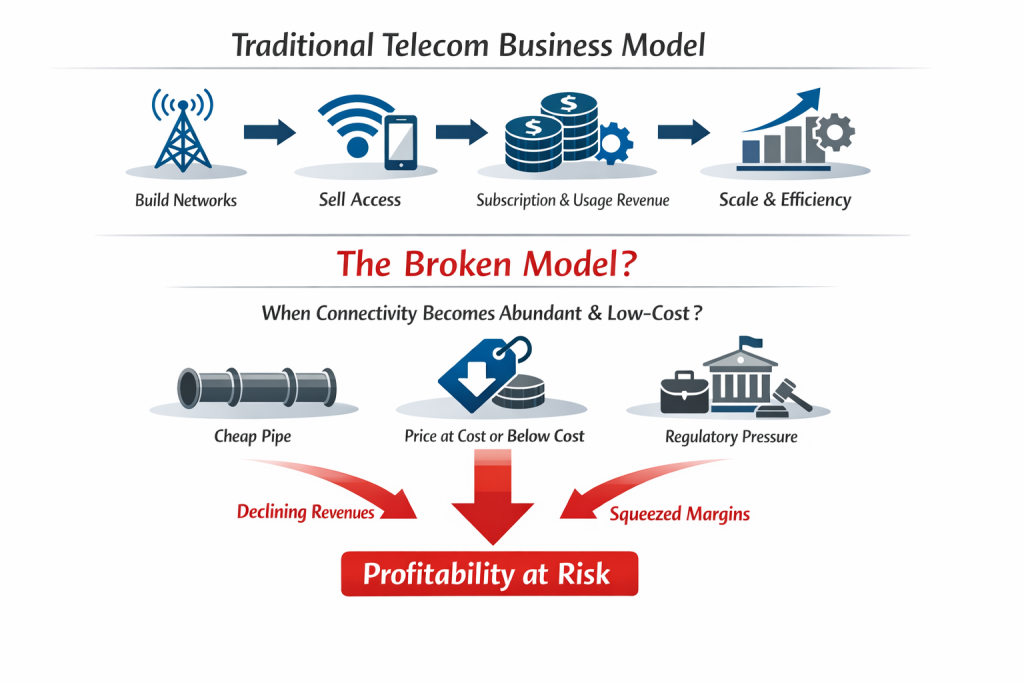
As seen in the diagram, for most of telecom history, the core business model has been simple: Build networks Sell access to those networks Recover capital (revenue) through subscription and usage revenues, and Protect margin through scale and operational efficiency But what happens if (when? after?) that model breaks? What happens if connectivity becomes so […]
With MWC upon us again, I thought I’d pose a question about how our industry, and the 500+ OSS/BSS vendor market within it, is currently evolving. Telcos spend billions on transformation programmes every year. They talk about massive disruption like cloud-native stacks, open architectures, AI-driven automation and next-generation digital experiences. On paper, it sounds like […]
Quants have become the rockstars of modern share trading – extracting powerful signals from oceans of data at near real-time speed. Trading firms invest billions in them and in infrastructure that will give them even the slightest timing edge. Yet while telcos drown in dashboards, the next competitive advantage may belong to the “NOC-star” – […]
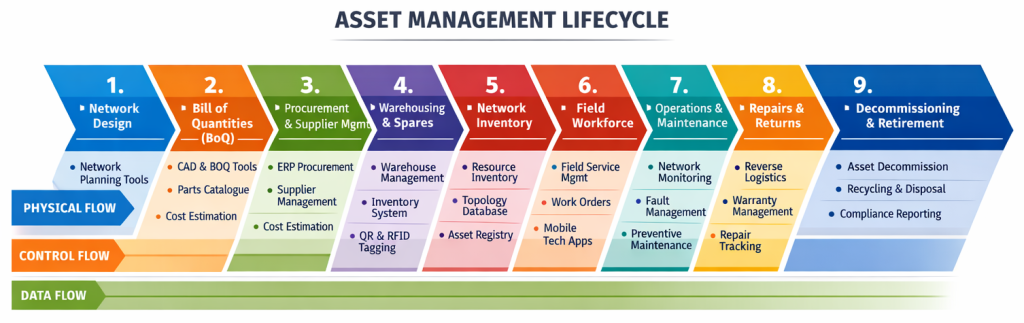
One of the things I find incredibly interesting when I look at the Simplified TAM diagram below is that of each of the arrows indicating a workflow, only one has systems that aren’t really designed to manage the operational workflow. Assurance has trouble tickets Fulfilment has service orders Field operations has work orders Even billing […]

Two goldfish are dropped into a new tank. One turns to the other and asks, “Do you know how to fire the cannon on this thing?” That single gag captures the moment when what you expected collapses and the script is flipped. It has similarities with what users experience when a software transformation is forced […]

What happens when a Software Engineer, Enterprise Architect and Network Ops Engineer walk into a bar?….. . You know that head-slap moment when you realise software is more hindrance than help? I had one such experience back in circa 2005, when I watched a genuinely brilliant network ops engineer spend an entire afternoon navigating tools […]
I’ve never achieved true autonomy in an end-to-end, complex telco environment. What follows is a hypothesis. I’d love to hear your thoughts and clarifications. What I have achieved are small autonomous solutions that did work nicely, until a single baseline parameter changed. Then assumptions broke, dependencies surfaced and entire solutions + datasets had to be […]

Many (myself included), believe that recent progress in AI-based technologies should accelerate digital transformation (even if only by inspiring us to think differently about the digital systems we already have). However, in Part 1 of this series we explored a paradox. The most common uses of AI today are not loosening the grip of legacy […]

In Part 1 of this series, we explored an uncomfortable paradox. AI is being excitedly positioned as the key to telco transformation, yet many initiatives are quietly reinforcing the same legacy digital landscapes they would love to replace. That leads to a more fundamental question. Before choosing AI models, architectures, or tooling, must we actually […]

We’re already seeing it. AI is slowly infiltrating telecom, one little project at a time… monitoring, automating, optimising. In AI, we have one of the most disruptive opportunities of our lifetime, but the results of telco AI projects to date still feel eerily familiar. Are most telcos using tomorrow’s tools with yesterday’s thinking? Maybe the […]

We know telco customers want faster speeds.But is it possible that we’re focussed on the wrong type of speed?Here’s a hint: the real drag isn’t line-speed. . “Finally”: The Message that Triggered an Article Late last week a friend pinged me with a SpeedTest screenshot and a single word: “finally.” I was confused. At first […]

Are you frustrated by the complexity of your OSS/BSS factory? With hundreds or even thousands of systems, all trying to juggle thousands of activities without dropping the ball is like organised chaos. But what if we’re looking at it all wrong, both in the way we’ve always designed our legacy application architectures and how we’re […]
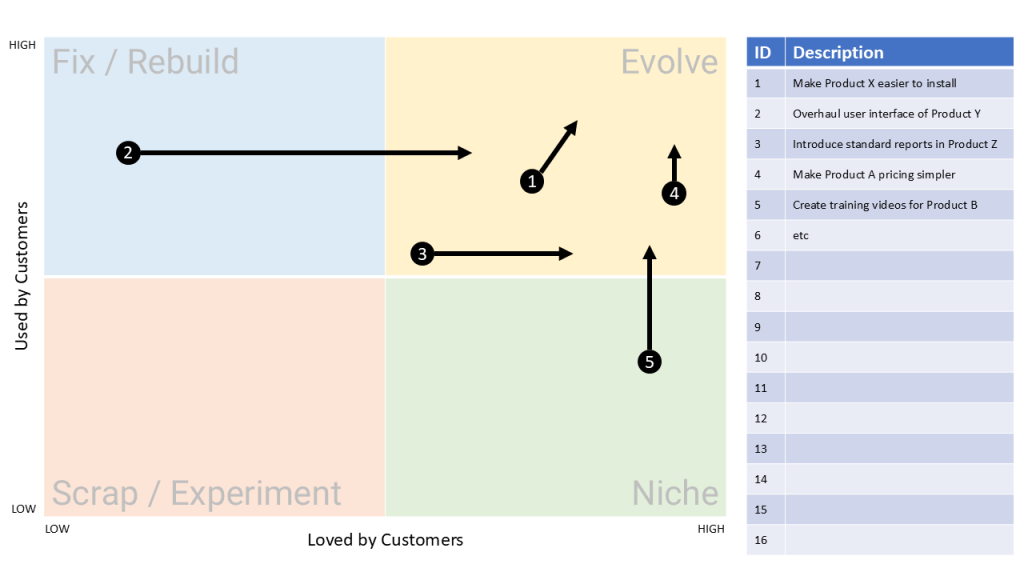
Most OSS/BSS roadmaps today overflow with novelty and buzz. You might even hear the words Agentic AI come up (not that I have anything against it but it can be a little over-hyped at times). But this series has taken a different path. We’ve looked at how to build a model that looks for enduring […]

Modern telco software roadmaps tend to be full of novel features. But what if none of that novelty is enduring? What if the silhouette of the Porsche 911 guides us on what should be included in our next OSS roadmap? The City Map From article 1 in this series, The Lindy Effect tells us that […]
After a major outage, we conduct PIRs (Post Incident Reviews). If we find something, we usually add controls. But when you think about it, that’s a bit like bandages on an infected wound – more layers, more failure points and potentially even a wider blast radius. The durable fix is more clinical: identify and remove […]