


For the World Cup Final, will You replace Messi with a Local Club Player to lower wage costs?
Given the topical theme of the World Cup final, we’ll go with a soccer story today. For the World Cup final, do you think Argentina
As the title suggests, this is the second part in a series describing a process flow visualisation, optimisation and decision support methodology that uses simple log data as input.
Yesterday’s post, part 1 in the series, showed the visualisation aspect in the form of a Sankey flow diagram.
This visualisation is exciting because it shows how your processes are actually flowing (or not), as opposed to the theoretical process diagrams that are laboriously created by BAs in conjunction with SMEs. It also shows which branches in the flow are actually being utilised and where inefficiencies are appearing (and are therefore optimisation targets).
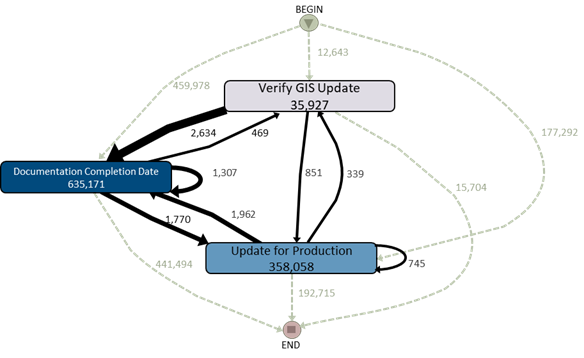
Some people have wondered how simple activity logs can be used to show the Sankey diagrams. Hopefully the diagram below helps to describe this. You scan the log data looking for variants / patterns of flows and overlay those onto a map of decision states (DPs). In the diagram above, there are only 3 DPs, but 303 different variants (sounds implausible, but there are many variants that do multiple loops through the 3 states and are therefore considered to be a different variant).

The numbers / weightings you see on the Sankey diagram are the number* of instances (of a single flow type) that have transitioned between two DPs / states.
* Note that this is not the same as the count value that appears in the Weightings table. We’ll get to that in tomorrow’s post when we describe how to use the weightings data for decision support.


Given the topical theme of the World Cup final, we’ll go with a soccer story today. For the World Cup final, do you think Argentina
For decades, scale gave large telcos purchasing power, infrastructure reach, extensive capability and millions of customers. It became one of the world’s most powerful and

Success in business, distilled to its simplest form, is often about arbitrage. The gap between supply and demand. The gap between value delivered and value
When it comes to OSS, the term Out of the Box (or OOTB) can be correct, incorrect and highly confusing all at the same time.