


For the World Cup Final, will You replace Messi with a Local Club Player to lower wage costs?
Given the topical theme of the World Cup final, we’ll go with a soccer story today. For the World Cup final, do you think Argentina
This is the third part of a series describing a really exciting analysis I’ve just finished.
Part 1 described how we can turn simple log files into a Sankey diagram that shows real-life process flows (not just a theoretical diagram drawn by BAs and SMEs), like below:
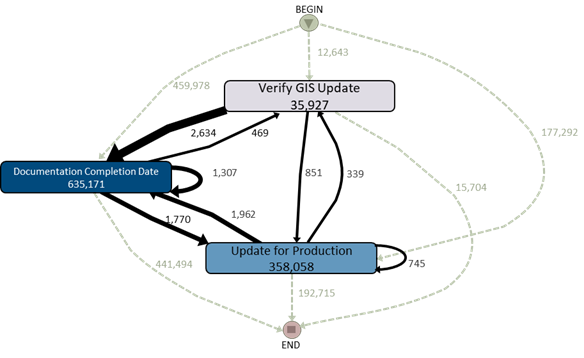
Part 2 described how the logs are broken down into a design tree and how we can assign weightings to each branch based on the data stored in the logs, as below:

I’ve already had lots of great feedback in relation to the Part 1 blog, especially from people who’ve had challenges capturing as-is process. The feedback has been greatly appreciated so I’m looking forward to helping them draw up their flow-charts on the way to helping optimise their process flows.
But that’s just the starting point. Today’s post is where things get really exciting (for me at least). Today we build on part 2 and not just record weightings, but use them to assist future decisions.
We can use the decision tree to “predict forward” and help operators / algorithms make optimal decisions whilst working towards process completion. We can use a feedback loop to steer an operator (or application) down the most optimal branches of the tree (and/or avoid the fall-out variants).
This allows us to create a closed-loop, self-optimising, Decision Support System (DSS), as follows:

Note: Diagram sourced from https://passionateaboutoss.com/closing-the-loop-to-make-better-decisions, where further explanation is provided
Using log data alone, we can perform decision optimisation based on “likelihood of success” or “time to complete” as per the weightings table. If supplemented with additional data, the weightings table could also allow decisions to be optimised by “cost to complete” or many other factors.
The model has the potential to be used in “real-time” mode, using the constant stream of process logs to continually refine and adapt. For example:
If you’re wondering how the DSS could be implemented, I can envisage a few ways:
Note: We’re now offering a service that uses this technique to document, benchmark and optimise operational processes directly from activity log files.



Given the topical theme of the World Cup final, we’ll go with a soccer story today. For the World Cup final, do you think Argentina
For decades, scale gave large telcos purchasing power, infrastructure reach, extensive capability and millions of customers. It became one of the world’s most powerful and

Success in business, distilled to its simplest form, is often about arbitrage. The gap between supply and demand. The gap between value delivered and value
When it comes to OSS, the term Out of the Box (or OOTB) can be correct, incorrect and highly confusing all at the same time.