Are your OSS teams working hard, but still finding that incidents, orders, data fixes, escalations, automation releases and transformation decisions move too slowly?
Most telcos assume the answer is another tool, another integration, another dashboard or another automation initiative.
That’s understandable because OSS transformation is usually framed as a technology problem.
However, the harder truth to face up to is that many OSS programmes don’t fully deliver after handover because the operating model was not adequately considered.
We end up with scenarios such as:
.
Our contrarian view is that the most important OSS design decision is not simply the system architecture.
It’s the combination of OSS/BSS plus operating model (OpsModel) that determines who is responsible for:
.

.
FWIW. We previously explored this risk in Did we forget the OSS operating model?
That article makes a simple observation: OSS transformations usually start with all the technical elements (ie use-cases, requirements, technical solutioning and implementation planning), leaving the future operations and organisation chart as an afterthought.
That’s dangerous because OSS doesn’t merely support operations. OSS transformation not only reshapes the technology, but also the operations (and potentially even entire business models in a chicken vs egg by-play).
As per the diagram below, OSS/BSS stacks underpin the entire telco business model, so we need to co-design the OpsModel and OSS/BSS stack in tandem.

Potential examples include:
This is also why the PAOSS OSS/BSS Use-Cases and Personas downloadable pack could be useful.
It describes over 70 personas and nearly 700 OSS/BSS use-cases.
It reinforces that OSS/BSS are far from being a single-user system. They’re an entire operating fabric across account managers, NOC operators, field teams, network architects, data specialists, service managers, billing teams, product teams, security teams, executives and many more. Exactly the personas impacted by your OpsModel.
That makes operating model design more than an HR or transformation-management artefact. It should sit beside architecture, data, process, integration, partnership agreements/contracts and delivery design from the beginning.
,
To design the future model, with all the possibilities that new tools and AI offer, it helps to understand the historical models most telcos are still carrying… and how to evolve from wherever their current-state lays.

Traditional network operations were organised around technical domains such as transmission, IP, RAN, core, access, field, facilities and switching.
Each tower owned expertise, tools, escalation paths and technical judgement. This model made sense when networks were more vertically integrated and deep domain expertise was scarce, but concentrated.
However, it also created operational silos. Inventory might sit with engineering. Fault management might sit with the NOC. Provisioning might sit with service delivery. Reporting might sit with operations support. Data quality might sit nowhere until a major order, outage, audit or regulatory issue exposed the gap.
.
As telcos matured, process frameworks such as TM Forum’s Business Process Framework, also known as eTOM and ITIL, helped organisations think beyond technical towers.
Fulfilment, assurance and billing became end-to-end process families. ITIL-style practices also influenced incident, problem, change and configuration management.
This improved process visibility, but it created another problem. Process owners could define ideal flows, yet execution still depended on domain teams, IT teams, OSS platform teams, BSS teams, field teams and suppliers. The process map looked clean. The hand-off paths often didn’t.
PAOSS’s How to Design Telecommunication Business Process Flows Using eTOM is a useful starting point for process mapping, but process mapping alone doesn’t define accountabilities, KPIs, escalation paths or AI decision rights.
.
Many telcos then created an OSS centre of excellence, OSS platform groups or shared services teams. This helped consolidate architecture, integration patterns, tooling standards, environments, release management and vendor coordination.
The limitation is that central OSS teams can become bottlenecks (further enhancing the traditional IT vs OT religious war).
If every change request, workflow update, API enhancement, data-quality rule and automation change has to pass through one central queue, the organisation gets governance overhead and potentially loses velocity.
.
Some telcos pushed accountability back to network domains. This improved domain ownership, but often reintroduced fragmentation. RAN, IP, optical, access, core and field teams each optimise for their own domain. That can create duplicated automations, inconsistent data definitions, local dashboards and conflicting escalation logic.
Federation works only when there’s a strong shared operating fabric: common metrics, common service models, common inventory confidence rules, common API principles and common automation governance.
Then digital-native thinking pushed telcos towards product-aligned teams, platform engineering, agile delivery, DevOps and SRE-style operating practices. In OSS terms, this means treating inventory, assurance, fulfilment, orchestration, data and APIs as internal products rather than back-office systems.
This is often healthier, but only if the product teams are aligned to operational outcomes:
This is the Mercedes Star to North Star problem. Different executive lenses can pull the transformation in different directions unless they roll up to a consistent operational metric hierarchy.
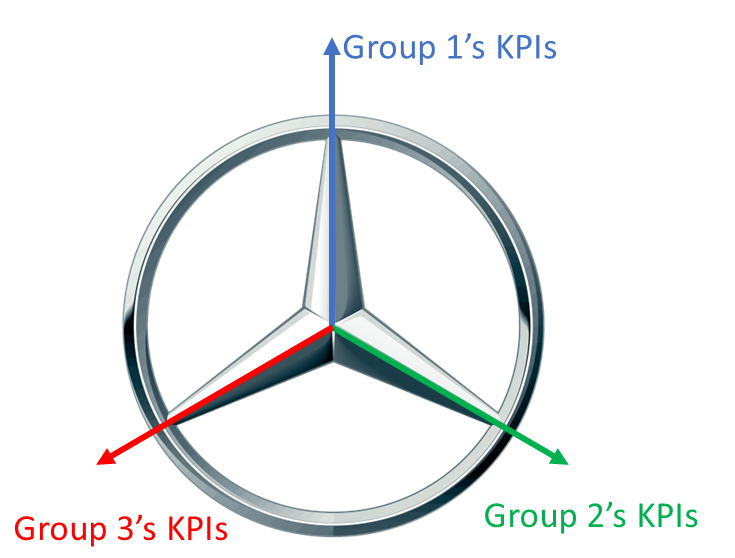
The emerging model is different again.
TM Forum’s Autonomous Networks mission, TM Forum’s Autonomous Operations Operating Model Use Case, ETSI’s Zero-touch network and Service Management work and ITU-T Y.3172 all point towards networks with higher levels of automation, autonomy, intelligence and closed-loop operation.
These aren’t just architecture shifts. They’re instigating significant operating-model shifts.
AI and agentic mechanisms introduce new questions:
The big shift isn’t instant autonomy. It’s the creation of faster, better-evidenced decision loops. HOwever, these loops are tending to evolve over time, so the OpsModel needs to be continually evolving in the process.
,
There isn’t a universal OSS organisation design because telcos differ by scale, network type, regulatory exposure, service mix, sourcing model, digital maturity and legacy complexity.
However, a mature OSS function usually needs explicit accountability across scope areas such as:
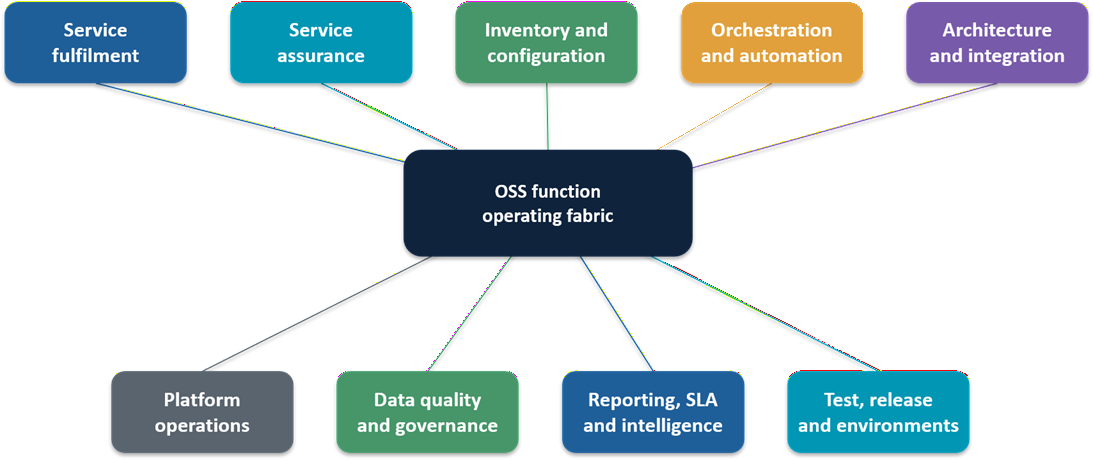
Service fulfilment covers the flow from commercial intent to activated service. This includes service qualification, order decomposition, design, assignment, activation, testing, fallout handling and hand-off into assurance. Fulfilment interfaces tightly with BSS, product catalogue, customer order management, service order management, network domains, field workforce and partners.
The key operating-model question is “Who owns the end-to-end order outcome when multiple teams, catalogues, resources, domains and suppliers are involved?”
.
Service assurance covers detection, correlation, impact analysis, prioritisation, restoration, communication, SLA management and continuous improvement. PAOSS’s Building the Ultimate Network and Service Assurance Framework treats assurance as the point where network health, service health, customer experience and SLA commitments intersect.
The key OpsModel question is whether assurance is measured around network events or customer-impacting service outcomes. They’re related, but they’re not the same thing. Modern OpsModels tend to be more focussed on customer experience measures rather than the traditional “nodal” KPIs like five-nines.
.
Inventory and configuration cover the lifecycle of physical, logical, virtual, cloud, service and customer-facing resource records. This includes design state, planned state, built state, discovered state, reconciled state and retired state.
PAOSS’s How is OSS/BSS service and resource availability supposed to work? may prove to be useful here because it explores the complexity of service and resource availability in modern OSS/BSS environments.
The key OpsModel question is who owns the asset management life-cycle across a variety of different systems and business units as highlighted below.
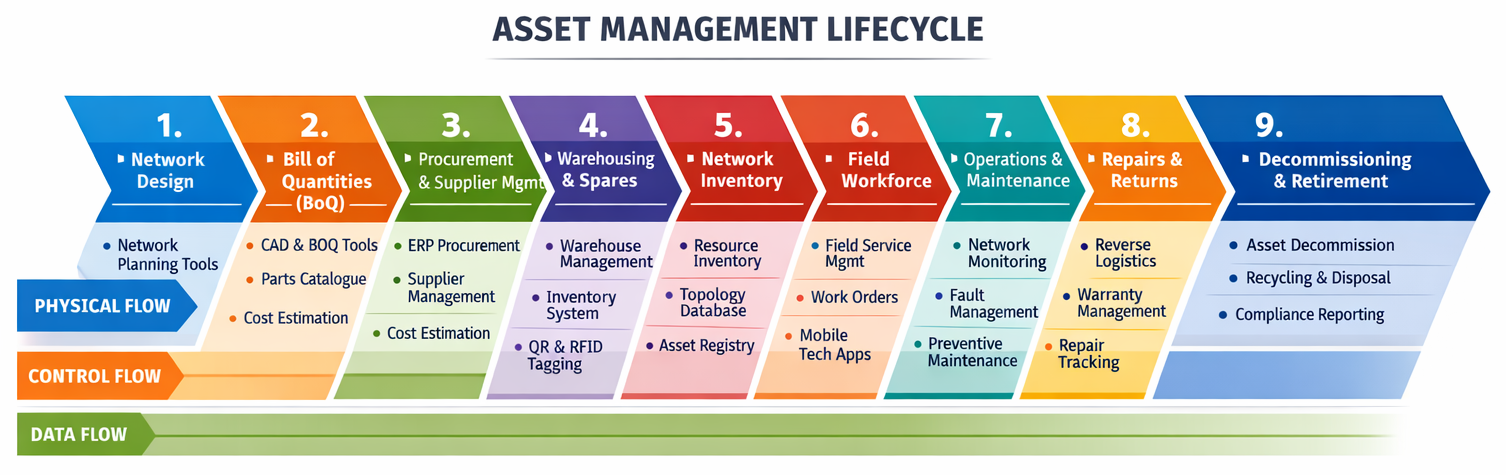
.
Orchestration and automation turn policies, designs, runbooks and workflow rules into repeatable operational actions. This increasingly spans fulfilment automation, assurance remediation, change automation, test automation, field dispatch automation and a variety of AI-assisted workflow executions.
The key operating-model question is who owns the authority to move a use-case from manual, to assisted, to recommended, to automated / closed-loop.
.
OSS architecture and integration cover capability design, component boundaries, API / integration patterns, event flows, mediation, data exchange, platform dependencies and enterprise alignment.
TM Forum’s Open Digital Architecture and Open APIs are useful reference points for thinking about OSS architecture and standardisation.
The key operating-model question is who is responsible for architecture decisions across the variety of groups that influence outcomes including enterprise architecture, security, platform, networks, systems or even engineering / integration standards.
.
OSS platform operations covers environment management, access, availability, performance, release readiness, observability, incident support, supplier coordination and technical debt management for OSS platforms.
The key operating-model question is whether OSS platforms are run as back-office applications or as operationally critical platforms whose reliability directly affects network, service and customer outcomes (this is the “IT” in the IT vs OT debate).
.
OSS data quality and governance cover data definitions, stewardship, system-of-record decisions, lineage, confidence scoring, reconciliation, remediation workflows and operational data-policy enforcement.
Our How to Design an OSS / Telco Data Governance Framework could be useful here because it frames data governance around service models, resources, quality and operational use.
We also love the idea of a DOC (or Data Operations Centre), which suggests that we should treat data fault fixes as systematically as we treat network fault fixes.
The key operating-model question is whether data governance sits close enough to the operational workflows that create and consume the data.
,
Reporting, SLA and operational intelligence cover KPI logic, SLA definitions, dashboard governance, incident evidence, regulatory reporting, operational analytics, executive reporting and AI performance reporting.
The key operating-model question is whether metrics roll up coherently to a North Star (as discussed previously), or whether teams are optimising against local targets that pull the operating model apart.
.
Test, release and environment management covers OSS regression testing, release governance, environment readiness, test data, deployment controls, rollback, training readiness and handover-to-operations.
It’s often overlooked, yet it becomes critical when OSS platforms become operational control systems (increasingly important where variants of DevOps are employed).
The key operating-model question is whether release cadence, platform stability, user adoption and operational risk are governed through one integrated model within your operations environment.
.
Different telcos need different organisation models, which are particularly influenced by partnership and supply chains. The right answer is rarely one pure pattern. Most mature operators use a hybrid of the following:
A centralised OSS CoE owns standards, roadmap, architecture, shared platforms, governance, integration patterns and vendor coordination. It’s useful when an operator has high fragmentation, duplicated tools, weak standards or inconsistent delivery practices.
The strength is coherence. The risk is bottlenecking.
.
Federated OSS teams sit close to network domains such as IP, optical, RAN, access, core and transport. They understand domain-specific rules, constraints and operational realities.
The strength is trust and control within teh domain. The risks are local optimisation, duplicate tooling and inconsistent operating practices.
.
A platform-product model treats OSS capabilities as internal products. Inventory, assurance, orchestration, integration, data and reporting have product owners, roadmaps, users, adoption metrics and value measures.
The strength is user focus and intra-domain control. The risk is that product metrics can drift away from enterprise operational outcomes unless a strong North-star prevails.
.
This model combines domain towers with cross-functional product squads. For example, an assurance squad might include OSS product ownership, NOC SMEs, data specialists, integration engineers, network-domain representatives and AI / automation specialists.
The strength is balance. It preserves domain expertise while creating outcome-oriented delivery. The risk is matrix complexity unless decision rights are clear.
.
Some operators rely heavily on managed service providers, systems integrators or vendor-led delivery. This can accelerate delivery and access scarce skills, but it can also weaken internal ownership of IP across architecture, data, automation rules and operational outcomes.
The strength is capacity. The risks include third-party dependency, tenure of expert resources and diluted accountability.
.
The following accountability model can be adapted for large, mid-sized or lean operators. In a small operator, one person or team may own several of these capabilities. In a large operator, each may become a dedicated function or product group.
| Team or capability | Core accountabilities | Typical operating-model risks to overcome |
|---|---|---|
| OSS Strategy and Architecture | Target architecture, capability roadmap, component boundaries, standards, patterns, transformation sequencing, technical debt strategy | Architecture becomes disconnected from the coal-face of operations |
| OSS Product Ownership | Backlog ownership, prioritisation, user journeys, business value, adoption, release scope, value realisation | Roadmaps optimise system features rather than operational outcomes |
| Fulfilment and Orchestration | Order decomposition, service design, assignment, activation, fallout handling, workflow automation, activation evidence | Fallouts are treated as localised exception handling rather than E2E process-design feedback |
| Assurance and AIOps | Event correlation, alarm enrichment, service impact, incident prioritisation, RCA support, remediation recommendations, restoration workflows | NOC, SOC, care and service teams see different versions of operational realities |
| Inventory, Discovery and Reconciliation | Resource and service models, discovery, reconciliation, topology confidence, data correction, lifecycle status, relationship modelling | No one owns the asset life-cycle (ie the gap between designed, built, discovered and customer-facing state, etc) |
| OSS Data Governance | Data definitions, data ownership, lineage, confidence scoring, quality rules, stewardship, remediation loops, AI data readiness | Data governance sits too far from operational workflows. Data scientists don’t always understand operational context |
| OSS Integration and APIs | API contracts, event flows, mediation, integration patterns, error handling, partner exposure, API lifecycle and observability | Point-to-point delivery wins locally but can create ongoing tech-debt |
| OSS Platform Operations | Availability, environments, access, performance, observability, platform incidents, release readiness, supplier coordination | OSS platforms are run like normal IT without operational context or awareness (the IT vs OT debate) |
| Reporting and Operational Intelligence | KPI definitions, SLA logic, executive dashboards, regulatory views, operational analytics, evidence trails, metric lineage | When KPIs don’t roll-up coherently, then the Mercedes Star scenario discussed earlier can occur. Different functions use different definitions for the same operational metric |
| Test, Release and Environment Management | Release planning, regression testing, environment governance, deployment controls, rollback, test data, operational readiness | Pressure on increased release cadence pulls against operational stability |
.
In reality, the operating model will generally comprise a large set of trade-offs. The best models make the trade-offs explicit.
Network domain SMEs understand how the network actually behaves. Platform teams understand how to build reusable, scalable, governed capabilities. If domain SMEs own everything, the operating model fragments. If platform teams own everything, the operating model loses operational trust.
The healthiest model separates domain expertise from platform engineering, but forces them to collaborate through shared decision rights, shared backlogs, joint acceptance criteria and common operational metrics.
.
Inventory isn’t just a database. It’s influence over many workflows can make it an important power base. Whoever owns the different parts of an asset management life-cycle influences fulfilment, assurance, automation, capacity, finance, regulatory reporting, service impact and customer communication.
This is why inventory ownership is often a federated stewardship model. Platform ownership can be centralised, but data ownership needs to be domain or outcome or process specific. Regardless, it needs to be lifecycle-aware, traceable from end-to-end and operationally accountable.
.
Automation needs a joint Network Engineering, OSS and IT governance model:
If any one of these groups governs automation alone, the model is incomplete. The future automation governance model should decide which use-cases are assist-only, recommend, act-with-approval or closed-loop. It should also define guardrails, rollback, approval paths, audit trails and evidence requirements.
This links directly to the message behind AN Level 4 is Like Putting a Man on the Moon, which argues that autonomous network ambitions should be treated as a strategy rather than a simple target. Autonomy requires changes to data, process, trust, accountability and execution rights.
.
Traditional assurance starts with network events. However, the traditional approach is also a reason why many telcos perform poorly on NPS measures.
What if we were to build our OpsModels around customer experience like Jeff Bezos rather than network events like typical telcos? Would other metrics like churn materially improve?
Care teams need customer-facing empathy, accuracy, speed and pragmatism. SLA teams need contractual precisions. Executives need a finger on the pulse of what’s happening at the coal-face and an ability to do something about it when the needle is moving towards negative outcomes.
The problem is these views are almost never reconciled:
They’re all linked via the OpsModel.
The assurance operating model must bridge NOC, Care, CRM, SLA reporting and customer communication. It should define how events become incidents, how incidents become service impacts, how service impacts become customer notifications and how customer impacts become SLA or executive metrics.
.
Data governance can’t sit purely in Enterprise Data or purely in Networks.
Enterprise Data teams are essential for standards, lineage, data products, analytics and governance. Network teams are essential for domain meaning, lifecycle ownership and operational correction. OSS sits between them.
If data governance sits purely in Enterprise Data, it can become too abstract. If it sits purely in Networks, it can become too domain-specific. The better model is shared governance where Enterprise Data owns common data principles, OSS owns operational data contracts and network domains own domain-specific truth.
.
The OSS function shouldn’t own everything. It should own the operating fabric that allows adjacent teams to work coherently and meet their operational objectives.
Clear demarcation is essential
| Adjacent team | Interface with OSS | Key demarcation question |
|---|---|---|
| Network Domains: IP, Optical, RAN, Access, Core, Transport | Provide domain rules, technical validation, topology interpretation, remediation patterns, data ownership and SME escalation | Who owns the truth of designed, built, configured and discovered network state? |
| Network Automation | Builds automations, runbooks, policy translations, intent mappings, domain adapters and execution mechanisms | Who decides whether an automation is safe enough to run without approval? |
| Enterprise Architecture | Aligns OSS with business architecture, application strategy, integration principles, domain architecture and transformation roadmaps | Who arbitrates when enterprise standards conflict with operational velocity? |
| IT Platforms | Operate infrastructure, cloud, identity, observability, CI/CD, middleware, ITSM and enterprise service foundations | Where does IT platform reliability end and OSS operational accountability begin? |
| Data, Analytics and AI | Supports semantic models, data products, analytics, AI governance, model management and enterprise data policies | Which metrics are operational system-of-record metrics versus analytical replicas? |
| Cybersecurity | Defines access controls, privileged actions, segregation, audit logging, threat controls, policy gates and AI guardrails | Which operational actions require security approval, additional logging or compensating controls? |
| Service Operations and NOC | Consumes assurance views, incident workflows, service impact, restoration recommendations, escalation paths and operational dashboards | Who owns incident command when the root cause spans multiple domains? |
| Field Workforce | Consumes work orders, site context, asset records, access details, test results and completion evidence | Who owns the feedback loop when field observations differ from OSS records? |
| Product, Commercial and Care | Defines service promises, product constructs, customer commitments, care messaging, offer feasibility and service experience needs | Who confirms that a product promise can be fulfilled and assured operationally? |
| Finance, Revenue Assurance and Regulatory | Consumes service evidence, billing triggers, asset data, SLA records, compliance reports, penalty logic and operational audit trails | Who owns the evidence when operational records affect revenue, penalties or regulatory obligations? |
A mature OSS operating model should define a metric hierarchy that prevents teams from optimising locally while damaging the whole system.
The Mercedes Star to North Star concept is useful again here. Finance, technology and operations often look at OSS transformation through different lenses. Finance may prioritise cost. Technology may prioritise architecture. Operations may prioritise stability. Customer teams may prioritise experience. If these aren’t reconciled, the transformation pulls in multiple directions.
A better model is to create a cascading metric structure. See here for a cheat-sheet on aligning different world views within a telco.
The critical design principle is metric roll-up.
.
Demarcation problems are where many OSS operations fail. Everyone agrees on the high-level process. The failure happens in the boundary conditions.
The operating model should define hand-offs in four layers:
This is where persona-led design becomes powerful. The PAOSS OSS/BSS Use-Cases and Personas download pack helps teams identify who interacts with OSS/BSS tools, what each persona is trying to achieve and indirectly, where the operational friction appears.
.
AI has and will continue to change the mechanics of how we work, so it also impacts OpsModels.
AI use-cases span (or have the potential to span) all parts of a telco’s business:
While there’s an initial focus on key areas such as AIOps and churn (ie only a NOC copilot or a chatbot), the AI of the future OpsModel will be a cross-functional operations force.
It’s likely to add cumulative value across the following maturity levels:
Assistive AI helps a user complete a task faster. Examples include summarising incidents, explaining topology, drafting customer messages, preparing release notes, interpreting alarms or guiding care agents. The human still owns judgement and execution.
Recommendation AI proposes the next-best action, likely root cause, probable fallout risk, likely SLA breach, optimal resource plan or remediation path. The human remains the decision-maker, but the operating model needs to define what evidence is required to trust the recommendation.
Agentic mechanisms prepare or execute a workflow after human approval. This is likely to be the dominant near-term model in telcos because it offers speed without removing human accountability. This is broadly consistent with Autonomous Networking Level 4. Examples include generating change plans, preparing order remediation, initiating inventory correction workflows, staging configuration changes or preparing customer communications.
Closed-loop automation allows the system to detect, decide and act within policy. This should be reserved for use-cases with high data confidence, low blast radius, strong rollback, clear observability and agreed accountability.
AI is likely to eliminate some roles in traditional Ops Models, but new roles created by AI-native operations may include:
These roles will need new and explicit accountabilities.
RACI templates aren’t perfect, but they’re useful when they force difficult conversations about ownership and accountability aspects of Ops Models.
They’re often scenario-specific and carrier-specific. The aim is to expose where ownership, accountability, consultation and communication actually change.
The following tables provide some activity / scenario based RACI models for consideration and comparison with your operations model.
| Activity | Responsible | Accountable | Consulted | Informed |
|---|---|---|---|---|
| Service qualification and feasibility | Fulfilment / orchestration team | Service delivery owner | Network domains, product, inventory | Sales, care, customer operations |
| Order decomposition and workflow routing | Fulfilment / orchestration team | OSS product owner | BSS, product catalogue, network domains | Service delivery, care |
| Activation and test evidence | Network domains / automation team | Service delivery owner | OSS platform, field, assurance | Care, customer operations |
| Fallout classification | Fulfilment operations | Service delivery owner | OSS, BSS, network domains | Sales, care |
| Fallout remediation and process feedback | Fulfilment operations / OSS product owner | Service delivery owner | Product, catalogue, network domains, field | Reporting, transformation office |
| Activity | Responsible | Accountable | Consulted | Informed |
|---|---|---|---|---|
| Event correlation and enrichment | Assurance / AIOps team | NOC operations owner | Network domains, inventory, data governance | Care, service management |
| Service impact assessment | Assurance / service impact team | Service operations owner | Inventory, product, care, SLA team | Executives, customer operations |
| Major incident escalation | NOC / service operations | Incident commander | Network domains, care, communications, security | Executives, affected business units |
| Customer-facing restoration estimate | Service operations / care communications | Customer operations owner | NOC, network domains, SLA team | Care agents, account teams |
| RCA and recurrence prevention | Problem management | Service operations owner | Network domains, OSS, data, automation | Care, product, finance, regulatory |
| SLA attribution and exclusions | SLA / reporting team | Service operations owner | Care, finance, legal, network domains | Executives, account teams |
| Activity | Responsible | Accountable | Consulted | Informed |
|---|---|---|---|---|
| Data model and lifecycle design | Inventory / OSS architecture | OSS architecture owner | Network domains, data, assurance, fulfilment | Enterprise architecture, reporting |
| Discovery and reconciliation | Inventory / discovery team | Inventory owner | Network domains, field, data governance | Assurance, fulfilment, finance |
| Data defect remediation | Domain data steward | Domain owner | Inventory team, field, OSS data governance | Assurance, fulfilment, reporting |
| Inventory confidence rules | OSS data governance | Inventory owner | Automation, assurance, network domains | Service operations, executives |
| Retirement and decommissioning | Network domain / inventory team | Domain owner | Finance, field, assurance, fulfilment | Reporting, regulatory where required |
| Discovered-versus-designed exception review | Inventory / reconciliation team | Inventory owner | Network domains, field, automation | NOC, service delivery |
| Authoritative-source arbitration | OSS data governance | Operations leadership | Enterprise data, network domains, finance | Architecture board, reporting |
| Activity | Responsible | Accountable | Consulted | Informed |
|---|---|---|---|---|
| Change impact assessment | Network domain owner | Change owner | Assurance, inventory, service operations, care | Customer operations, SLA team |
| Service and customer impact modelling | Assurance / inventory team | Service operations owner | Network domains, product, care | Executives, reporting |
| Change execution | Network domain / automation team | Change owner | OSS platform, NOC, cybersecurity | Care, service operations |
| Post-change validation | Assurance / test automation | Change owner | NOC, inventory, service delivery | Care, reporting |
| Rollback decision | Change owner / NOC | Operations leadership | Network domains, assurance, cybersecurity | Executives, care, field |
| Activity | Responsible | Accountable | Consulted | Informed |
|---|---|---|---|---|
| Automation use-case selection | Automation product owner | Operations leadership | Network domains, OSS, IT, risk, cybersecurity | NOC, field, care |
| Automation design and build | Network automation / OSS engineering | Automation product owner | Network domains, inventory, integration, security | Service operations |
| Guardrail and rollback design | Automation engineering | Automation product owner | Network domains, cybersecurity, NOC | Risk, service operations |
| Closed-loop eligibility decision | Automation governance cell | Operations leadership | Network domains, risk, security, assurance | NOC, executives |
| Automation monitoring and rollback | OSS platform operations | Automation product owner | NOC, network domains, cybersecurity | Service operations, reporting |
| Post-release value review | Automation product owner | Operations leadership | Reporting, NOC, field, care | Transformation office |
| Activity | Responsible | Accountable | Consulted | Informed |
|---|---|---|---|---|
| Data defect detection | OSS data governance / discovery team | Data governance owner | Network domains, inventory, assurance | Fulfilment, reporting |
| Root cause classification | Domain data steward | Domain owner | OSS data governance, field, platform operations | Assurance, fulfilment |
| Correction and validation | Domain data steward / inventory team | Inventory owner | Network domains, field, assurance | Reporting, automation |
| Policy or workflow improvement | OSS product owner | Operations leadership | Data governance, network domains, training | All affected users |
| Activity | Responsible | Accountable | Consulted | Informed |
|---|---|---|---|---|
| Incident detection and triage | NOC / assurance team | NOC operations owner | Network domains, security, service operations | Care, field, executives |
| Customer and SLA impact confirmation | Service operations / SLA team | Customer operations owner | Assurance, care, product, finance | Executives, regulatory where required |
| Problem investigation | Problem management | Service operations owner | Network domains, OSS, data, automation | NOC, care, reporting |
| RCA evidence and prevention actions | Problem management / domain owner | Operations leadership | OSS, assurance, automation, change | Executives, customer operations |
| Problem backlog prioritisation | Problem management | Service operations owner | Network domains, product, finance | NOC, care, transformation office |
| Activity | Responsible | Accountable | Consulted | Informed |
|---|---|---|---|---|
| Release planning | OSS product owner / release manager | OSS platform owner | Operations, IT, security, affected domains | All affected users |
| Regression and operational readiness testing | Test and environment team | Release manager | NOC, fulfilment, assurance, inventory, field | Operations leadership |
| Deployment and rollback | OSS platform operations | OSS platform owner | IT platforms, cybersecurity, supplier support | NOC, service desk, affected users |
| Post-release adoption and value tracking | OSS product owner | Business owner | Reporting, operations, training, change management | Executives, users |
| Operational hypercare exit | Release manager / platform operations | OSS platform owner | NOC, service desk, affected product owners | Operations leadership, users |
| Known-error and training update | Service desk / training lead | OSS product owner | Platform operations, release manager, NOC | All affected users |
.
A practical target model for a mid-to-large telco could use a hybrid structure:
This model avoids two extremes. It avoids a fully centralised OSS bureaucracy that slows everything down. It also avoids a fully federated model where every domain creates its own tools, data definitions, automations and metrics.
The goal is a shared operating fabric with enough domain ownership to maintain trust.
The fastest way to make this practical is to start with personas and use-cases.
The PAOSS OSS/BSS Use-Cases and Personas download pack provides a starting point because it exposes the breadth of roles that interact with OSS/BSS.
For operating-model design, the persona catalogue can be used to answer:
.
The operating model document should be the master artefact that brings all the supporting artefacts together. It should not be a theoretical org-design document. It should explain how the OSS function works in practice: who owns what, how decisions are made, how work flows, how metrics roll up, how escalations move and how AI / automation is governed.
A typical OSS operating model document might use the following table of contents.
| Section | Typical contents | Purpose |
|---|---|---|
| 1. Executive summary | Purpose of the operating model, key design decisions, target-state summary, major changes from current state and priority actions | Allows executives to understand what is changing and why |
| 2. Operating model context and objectives | Business drivers, OSS transformation objectives, current pain points, strategic outcomes, constraints and assumptions | Connects the operating model to the transformation rationale |
| 3. Key Contacts | Quick contact list for easy reference | In the heat of operations, speed of support is of the essence |
| 4. Scope of the OSS functions | Included and excluded capabilities across fulfilment, assurance, inventory, orchestration, automation, architecture, integration, platform operations, data governance, reporting and release management | Clarifies what OSS owns, shares or doesn’t own |
| 5. Summarised operating model | Existing teams, processes, tools, decision rights, hand-offs, escalations, pain points, duplicated responsibilities and known ambiguity | Creates a baseline for change and exposes inherited operating-model debt |
| 6. Organisation design | Team structure, centralised versus federated responsibilities, product squads, CoE functions, domain interfaces and sourcing model (partnerships, supply chains, etc) | Shows how teams should be structured to support the operating model |
| 7. Team-by-team accountabilities | Responsibilities for OSS strategy, product ownership, fulfilment, assurance, inventory, data governance, integration, platform operations, reporting, test and release management | Defines who owns each capability and operational outcome |
| 8. Key Processes and workflows | Key operational flows such as major incident management (including comms planning), order-to-activate, detect-to-restore, change-to-assure, data-defect-to-remediation, automation-release-to-value and incident-to-RCA, (or any other major workflows applicable in your organisation) | Shows how work moves across teams, systems and decision points |
| 9. Decision rights and governance | Decision forums, approval rights, escalation thresholds, architectural governance, automation governance, data governance and change governance | Clarifies how decisions are made and who has authority |
| 10. RACI and accountability matrices (if not already incorporated in prior sections) | Scenario-specific RACI tables for fulfilment, assurance, inventory lifecycle, network change, automation release, data remediation, incident / problem / RCA and OSS platform release | Turns broad accountabilities into scenario-level ownership |
| 11. Interfaces with adjacent teams | Demarcation with network domains, network automation, enterprise architecture, IT platforms, data / analytics / AI, cybersecurity, NOC, field, product, care, finance, revenue assurance and regulatory teams. Also includes hand-offs and escalations across these interfaces | Prevents ambiguity at cross-functional boundaries. Clarifies what happens when normal flow breaks down |
| 12. KPI, SLA and operational intelligence model | North Star metrics, outcome KPIs, flow KPIs, quality KPIs, control KPIs, value KPIs, SLA logic, attribution rules, exclusions and dashboard ownership | Ensures metrics roll up consistently rather than pulling teams in opposite directions |
| 13. AI, automation and agentic operations model (if applicable) | Automation levels, AI use-case ownership, human-in-the-loop controls, closed-loop eligibility, agent governance, evidence trails, model drift, prompt drift and rollback rules | Defines how AI and automation change operating responsibilities |
| 14. Risks, controls and unresolved decisions | Operating-model risks, open decisions, policy gaps, ownership conflicts, dependency risks, adoption risks and mitigation actions | Makes unresolved ambiguity visible rather than hiding it in delivery |
| 15. Business COntinuity | Describes how the OpsModel will be tested and updated | Enforces ongoing evolution and improvement |
| 16. Appendices and supporting artefacts | Capability maps, org charts, persona maps, use-case matrices, process flows, RACI templates, KPI dictionary, SLA dictionary, data ownership matrix, glossary and reference models | Keeps the main document readable while preserving detail |
The key is that the operating model document should be treated as a living design artefact, not a one-off deliverable. It should be updated as the OSS architecture, process design, automation roadmap, AI use-cases, sourcing model and transformation sequencing evolve.
.
A complete OSS operating model shouldn’t be a 200-page document that nobody uses. It should be a concise set of practical artefacts that are referenced during design, delivery and suited for quick access under the pressure of daily operations.
Other documents might include:
| Artefact | Purpose |
|---|---|
| OSS capability map | Defines which capabilities sit inside OSS, adjacent teams or shared ownership |
| Organisation design pattern | Defines whether the model is centralised, federated, platform-product, hybrid or outsourced |
| Team accountability map | Shows who owns each capability, platform, process, decision and data domain |
| Persona and use-case matrix | Connects users, scenarios, workflows, pain points and adoption requirements |
| RACI and decision-rights matrix | Clarifies ownership for normal flow, exception flow, escalation and approval |
| Data ownership and confidence model | Defines system of record, stewardship, quality rules, confidence scores and remediation |
| KPI and SLA hierarchy | Aligns team-level metrics to operational outcomes and executive North Star metrics |
| Automation eligibility matrix | Defines assist, recommend, act-with-approval and closed-loop criteria |
| Escalation and hand-off playbook | Defines boundary conditions, evidence requirements, transfer points and ownership changes |
| AI governance and observability model | Defines agent ownership, audit trails, model drift, prompt drift, policy controls and human oversight |
There’s a simple test for any OSS operating model. Does it help the organisation make better operational decisions faster?
If the answer is no, the model is probably too abstract. If it defines teams but not decisions, it won’t help. If it defines processes but not demarcation, it won’t help. If it defines KPIs but not roll-up logic, it’ll create Mercedes Star misalignment. If it defines AI use-cases but not agent ownership, automation level and evidence requirements, it’ll create impressive demos but limited operational trust.
The OSS operating model isn’t just an org chart. It’s a decision architecture. It connects personas, use-cases, platforms, data, processes, KPIs, SLAs, escalation paths, automation policies and AI agents into one coherent operating fabric.
The telcos that get this right won’t simply have better OSS. They’ll have faster restoration, cleaner fulfilment, more reliable data, safer automation, clearer accountabilities and a better path to autonomous operations.
The telcos that ignore it will keep discovering that new tools and transformation efforts won’t fix old operating-model ambiguity.
That’s why operating model design should move from the margins of OSS transformation to the centre.
.
If you’re planning an OSS transformation, introducing AI-assisted operations or trying to clarify ownership across fulfilment, assurance, inventory, automation, data and adjacent network / IT teams, PAOSS can help you design the operating model before ambiguity slows the programme down.
We can help you map personas, use-cases, decision rights, RACI models, KPIs, SLAs, escalation paths, automation gates and AI governance into one coherent operating model that’s practical enough to use in real delivery.
Register your interest in PAOSS support for your OSS operating model design here:
