


Share Traders Invest Billions on Signal. Telcos Invest in Noise
Quants have become the rockstars of modern share trading – extracting powerful signals from oceans of data at near real-time speed. Trading firms invest billions
One of the things I find incredibly interesting when I look at the Simplified TAM diagram below is that of each of the arrows indicating a workflow, only one has systems that aren’t really designed to manage the operational workflow.
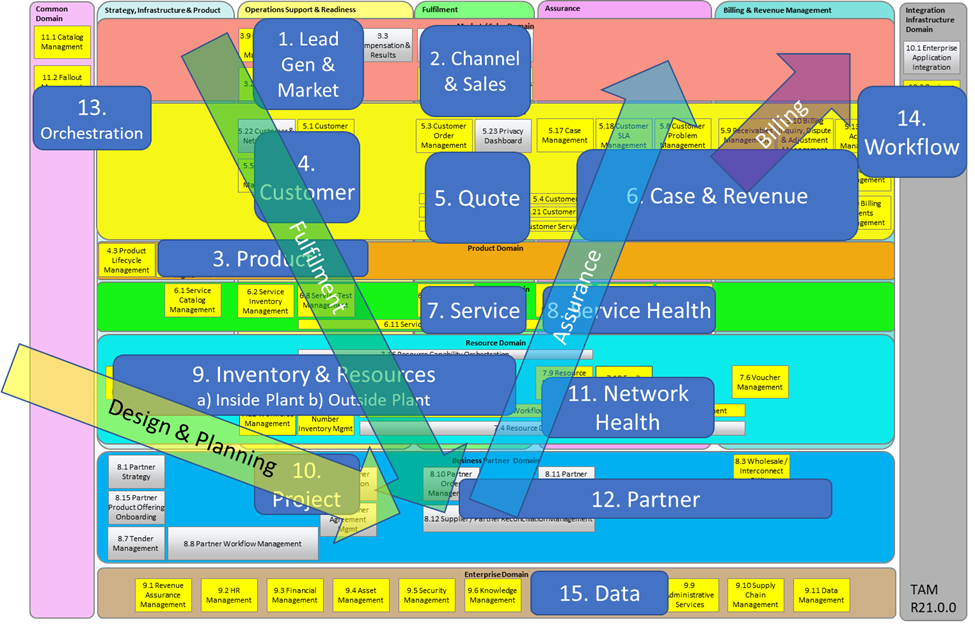
Do you also find it interesting that network inventory was never designed as a workflow-native system?
But, how do we make it so?
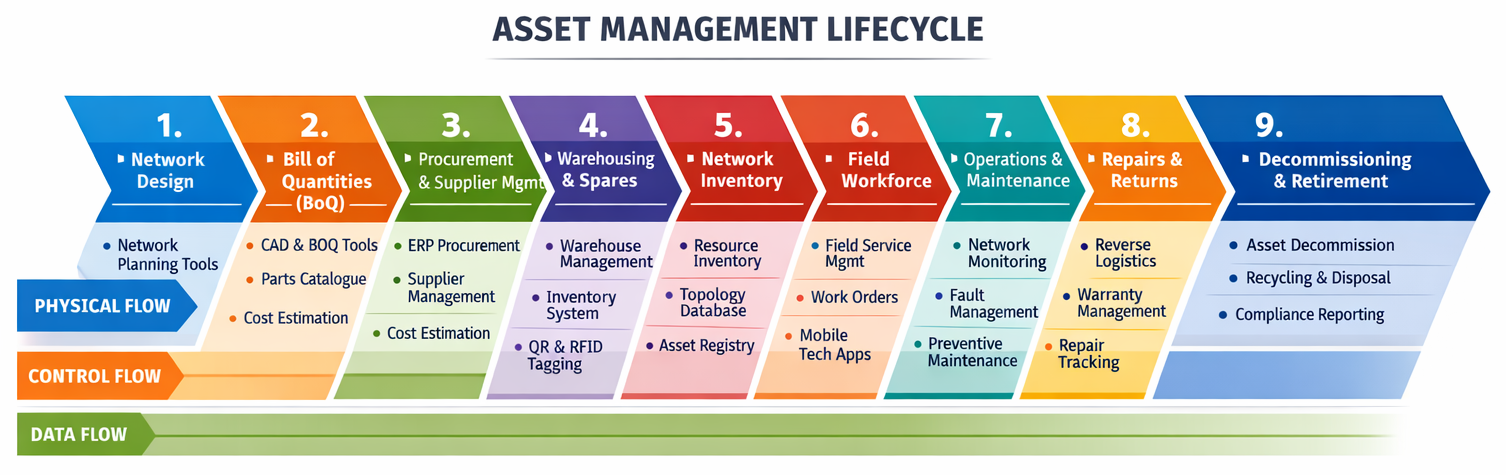
I believe we should take a closer look at a sample / simplified asset management lifecycle, such as the diagram below.
What do you notice about it?
From the chevrons and dot-points under them, there are actually a huge number of different systems and flows involved. We’ll explore that in more detail.
Whenever I think about architecting an OSS, my first thoughts tend start with Network inventory as it’s the repository that is most responsible for holding all information about the network’s resources, with associations to services and customers (amongst many other things).
Yet, by design, almost all Network inventory solutions are based on a state repository architecture, not a state transition engine.
That design assumption might have made sense when networks were slower, hardware-driven and operational models were siloed.
But even then, it still doesn’t make sense in a world where assets are continuously moving through design, procurement, deployment, optimisation and retirement loops. If this were true in the more static networks of yesteryear, it’s even more true of today’s more dynamic networks.
The lifecycle shown in the asset lifecycle diagram makes something very clear:
It also introduces three invisible planes:
Many failures happen when these planes get out of synch.
These discrepancies create seven systemic consequences that most operators have simply normalised:
Inventory knows what exists
Workflow tools know what is happening
No platform truly understands what is happening to what exists across time.
Are you getting the sense that this gap is far more strategic than it first appears?
To me, this suggests an opportunity for a new class of product.
A network inventory product built around a simple premise:
Treat the asset lifecycle itself as the primary workflow
Not just an asset and connectivity repository
Not procurement workflows
Not service workflows
Not maintenance workflows
But a single orchestrated workflow (Plan to Build to Operate – P2B2O), that manages the lifecycle graph where the asset is the anchor object.
Such a platform would fundamentally change the operating posture of a telco:
There are also two deeper architectural implications worth calling out:
Whoever builds the lifecycle-native control plane effectively creates the economic nervous system of the operator. When linked together with fulfilment, assurance and billing workflows, it tracks all aspects of the ROI:

This new solution becomes an Asset Lifecycle Operating System that sits horizontally across the stack and quietly eliminates hundreds of micro-frictions that operators currently just accept as unavoidable.
If anyone actually builds this, the question will become “Why were these myriad solutions ever separate?”
However, I’m the first to acknowledge that this is an ideal end-state.
Reaching the ideal of a Lifecycle Operating System for network assets is not primarily a technology challenge. It is a human-factor problem.
ERP teams optimise for financial control, warehouse teams for stock accuracy, field organisations for execution velocity, network teams for uptime and procurement for cost discipline. Each has evolved its own tools, data models, approval structures and risk tolerances over decades.
Those systems are not loosely connected components waiting to be orchestrated. They are deeply entangled embedded operating environments with contractual dependencies, audit implications and ways-of-working.
Attempting to unify them is less like integrating software and more like realigning tectonic plates (or convincing Liverpool and Arsenal to merge).
Even when Open APIs exist, semantic misalignment remains. The same asset can mean a capital object in finance, a serialised unit in logistics, a configuration endpoint in the network and a directly swappable component in maintenance.
Resolving those competing truths requires more than integration. It demands agreement on operational authority, which is where most transformation programmes quietly stall.
The vendor creating such a product would need to get all the siloes of every client / prospect aligned and signed-off.
This is why the path to a lifecycle-native operating model is far more likely to be evolutionary.
The winning pattern will probably not begin with a grand platform replacement, but by evolving Network Inventory product user interfaces to be more process-centric. I’ve started to see some evidence of vendors thinking of UI/UX/CX being process-driven.
The end state is unquestionably difficult, but the stepping-stones to get there are not totally implausible.
We need to first inform everyone who will listen that current-day operational drag is so huge, that architectural reinvention of these collective tools is an economic necessity.
Who’s with me?? 😀


Quants have become the rockstars of modern share trading – extracting powerful signals from oceans of data at near real-time speed. Trading firms invest billions
The OSS/BSS vendor landscape just crossed another threshold. The Passionate About OSS Blue Book OSS/BSS Vendor Directory has now grown to over 750 listings, giving

Two goldfish are dropped into a new tank. One turns to the other and asks, “Do you know how to fire the cannon on this

What happens when a Software Engineer, Enterprise Architect and Network Ops Engineer walk into a bar?….. . You know that head-slap moment when you realise