


The Age-Old IT vs OT Debate: Who gets the Keys to Your OSS?
For decades, organisations have argued over whether IT or operations (OT) teams should control the OSS environment, as though it’s a binary decision. Giving one
Many different user journeys flow through our OSS every day. These include external / customer journeys, internal / operator journeys and possibly even machines-to-machine or system journeys. Unfortunately, not all of these journeys are correctly completed through to resolution.
The incomplete or unsatisfactory journeys could include inter-system fall-outs, customer complaints, service quality issues, and many more.
If we categorise and graph these unsuccessful journeys, we will often find a graph like the one below. This example shows that a small number of journey categories account for a large proportion of the problematic journeys. However, it also shows a long tail of other categories that are individually insignificant, but collectively significant.
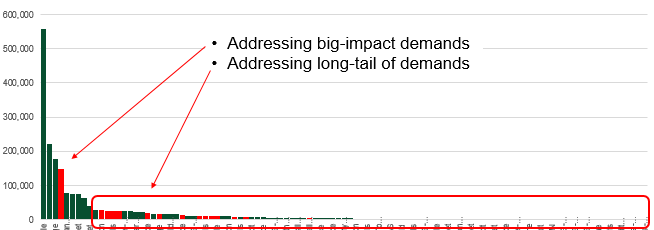
The place where everybody starts (including me) is to focus on the big wins on lhe left side of the graph. lt makes sense that this is where your efforts will have the biggest impacts. Unfortunately, since that’s where everybody focuses effort, chances are the significant gains have already been achieved and optimisation is already quite high (but numbers are still high due constraints within the existing solution stack).
The long tail intrigues me. It’s harder to build a business case for because there are many causes and little return for solving them. Alternatively, if we can slowly and systematically remove many of these rarer events, we’re removing the noise and narrowing our focus on the signal, thus simplifying our overall solution.
Since they’re statistically rarer, we can often afford to be more ruthless in the ways that we prevent them from occurring. But how do we identify and prevent them?
Each of the bars on the chart above represent leaves on a decision tree (faulty leaves in this case). If we work our way back up the branches, we can ruthlessly prune. Examples could be:
I’m sure you can think of many more, especially when you start tracing back up decision trees with a pruning saw in hand!!


For decades, organisations have argued over whether IT or operations (OT) teams should control the OSS environment, as though it’s a binary decision. Giving one
Given the topical theme of the World Cup final, we’ll go with a soccer story today. For the World Cup final, do you think Argentina
For decades, scale gave large telcos purchasing power, infrastructure reach, extensive capability and millions of customers. It became one of the world’s most powerful and

Success in business, distilled to its simplest form, is often about arbitrage. The gap between supply and demand. The gap between value delivered and value