Given the topical theme of the World Cup final, we’ll go with a soccer story today. For the World Cup final, do you think Argentina ever considered replacing Messi with an attacking midfielder from a local Argentinian club simply because his wages are lower? Of course they wouldn’t. Not because the local player is useless. […]
For decades, scale gave large telcos purchasing power, infrastructure reach, extensive capability and millions of customers. It became one of the world’s most powerful and durable business models. But scale and complexity has created thousands of dependencies across OSS, BSS, networks, processes, vendors and people. Clay Christensen showed that disruption often begins with something that […]
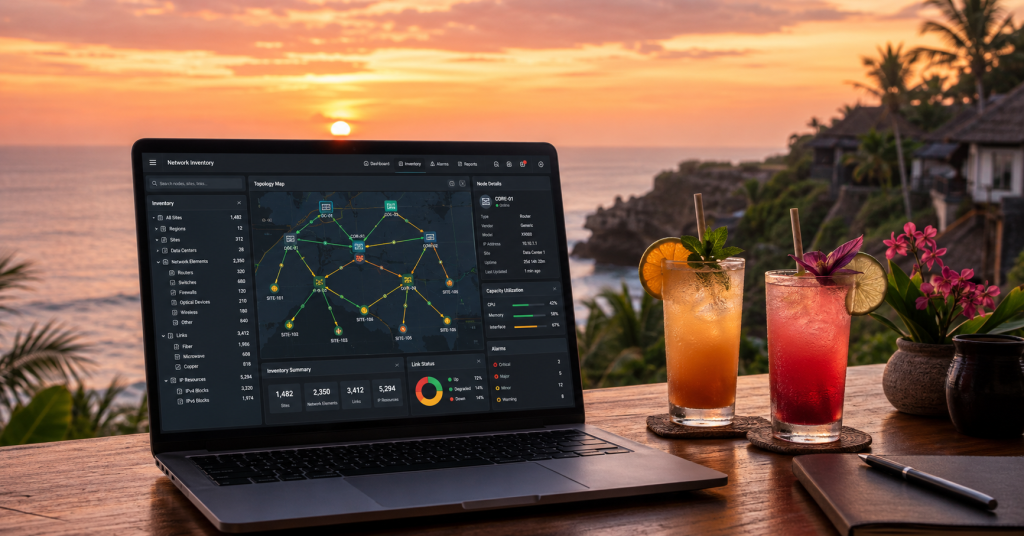
Success in business, distilled to its simplest form, is often about arbitrage. The gap between supply and demand. The gap between value delivered and value received in return. In the OSS industry, we tend to view arbitrage through a technical lens – better automation, AI, features, use cases, architecture and transformation. But a recent trip […]
Since OSS were first built, they’ve been designed around the belief that more complete information creates better operations. That belief made sense when they were designed by Engineers for Engineers. When network, service, customer, inventory, topology and assurance data was scarce, fragmented and hard to access. The organisation with the best information usually had the […]
Daniel Priestley recently highlighted something as important for business owners as telcos seeking out their next OSS or BSS solution: “If I said to you, go and build your dream house, the first thing you’d do is imagine the finished product. You’d drive around beautiful neighbourhoods, look at the ones you wish you lived in, […]
In the the last month or so 8 different carriers, from a variety of places around the planet, have reached out to us to discuss their ambitions for reaching AN Level 4. There’s clearly a major groundswell behind it. The thing about AN Level 4 is it sounds like a clear destination. But it doesn’t […]
Most OSS experts focus on the implementation and post-go-live performance aspects of a transformation. That makes perfect sense, because they’re the most visible phases. But by the time implementation begins, many of the decisions that shape success or failure have already been set in place. The pre-implementation phase is often underestimated – treated as a […]
Telco keeps talking about being scared of an imminent skills cliff. But perhaps the real problem is not just that experienced people are leaving. It’s that the industry has stopped feeling like the natural destination for the next generation of brilliant minds. Meanwhile, the industry’s hardest problems – automation, AI-native operations, complex transformation, data integrity, […]

Phone books now look like a relic from another era. Stone. Cold. Dead. But they were once one of the most powerful business growth engines in the world. Owned by telcos! As they declined in importance, Telcos didn’t just lose a directory. They totally forgot they were matchmakers. Phone books were never just paper directories. […]
I have a really important question for you to ask yourself today. It’s a question that shapes a lot of our thinking about how I can help the OSS/BSS/telco industry. How does what I do make more money for clients? Not just what your company does. Not what your brand says on the website. Not […]

We’re releasing our latest report today. Click on the image below to download it. Why are transformation approvals (eg business case approvals, vendor selections, project transformation decisions) forced to look perfect when delivery is anything but? That is the quiet contradiction at the heart of many (most?) digital transformation programmes. We build business cases as […]
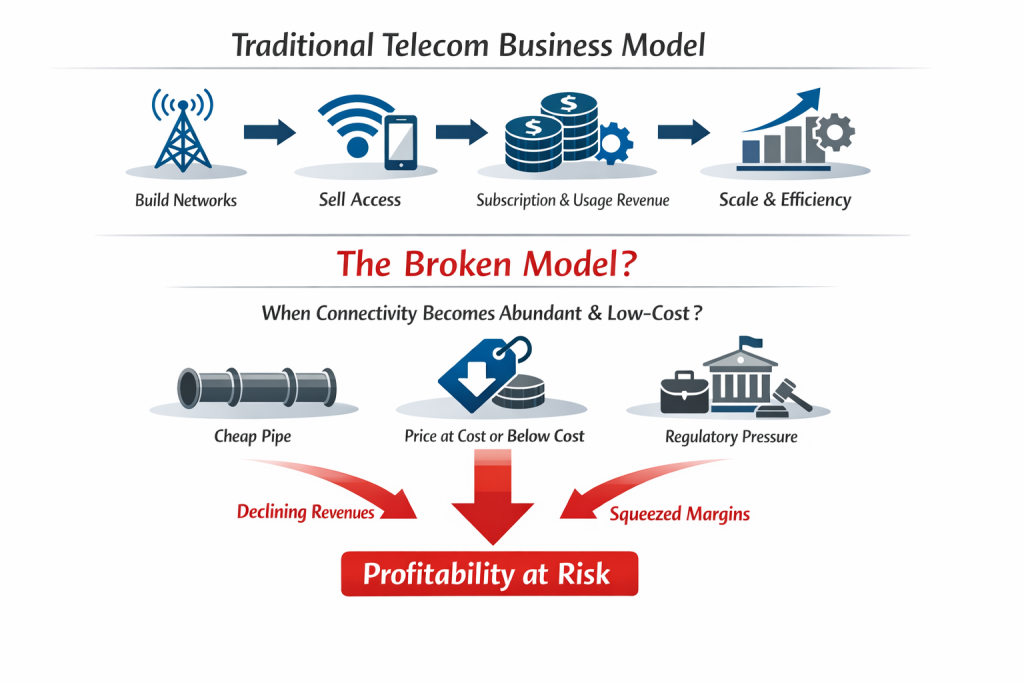
As seen in the diagram, for most of telecom history, the core business model has been simple: Build networks Sell access to those networks Recover capital (revenue) through subscription and usage revenues, and Protect margin through scale and operational efficiency But what happens if (when? after?) that model breaks? What happens if connectivity becomes so […]
With MWC upon us again, I thought I’d pose a question about how our industry, and the 500+ OSS/BSS vendor market within it, is currently evolving. Telcos spend billions on transformation programmes every year. They talk about massive disruption like cloud-native stacks, open architectures, AI-driven automation and next-generation digital experiences. On paper, it sounds like […]
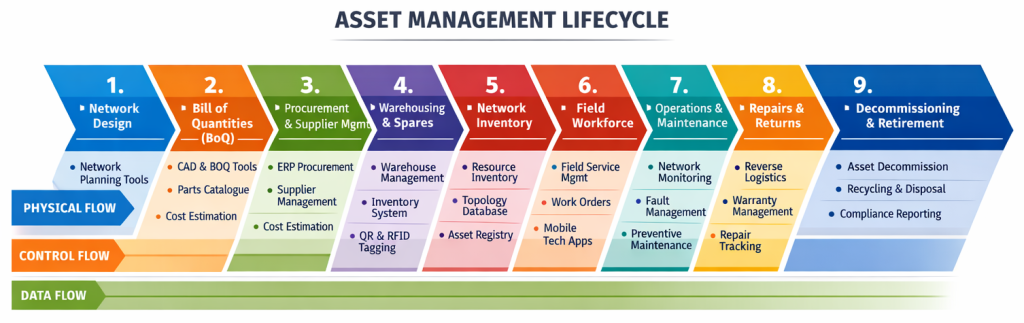
One of the things I find incredibly interesting when I look at the Simplified TAM diagram below is that of each of the arrows indicating a workflow, only one has systems that aren’t really designed to manage the operational workflow. Assurance has trouble tickets Fulfilment has service orders Field operations has work orders Even billing […]
Have you ever wondered why there’s such a big deal made of the start of a marriage (there’s a whole industry built around engagements and weddings), but there’s almost no fanfare at the end? Samuel Thompson pointed this out on Greg Isenberg’s podcast. Samuel highlighted that there are lots of products designed for the start […]

Whether we like it or not, most of us judge books by their covers. Sometimes that’s visual. Sometimes it’s the title. But here’s a thing I find interesting. Having written a couple of books myself, a lot of thought goes into choosing the title to resonate with the viewing audience. And yet, sometimes a title […]

Like microservices before it, AI and agentic solutions are increasingly seen as the panacea of digital transformation. In telco circles, AI is often framed as the fastest path to escape. A way to finally move beyond the clunky, legacy worlds of OSS/BSS. Piecemeal AI projects promise quick wins, modern capabilities, and a stepping stone towards […]

We’re already seeing it. AI is slowly infiltrating telecom, one little project at a time… monitoring, automating, optimising. In AI, we have one of the most disruptive opportunities of our lifetime, but the results of telco AI projects to date still feel eerily familiar. Are most telcos using tomorrow’s tools with yesterday’s thinking? Maybe the […]

Are you frustrated by the complexity of your OSS/BSS factory? With hundreds or even thousands of systems, all trying to juggle thousands of activities without dropping the ball is like organised chaos. But what if we’re looking at it all wrong, both in the way we’ve always designed our legacy application architectures and how we’re […]

Are you worried that your OSS/BSS stack, or parts of it, might be in desperate need of an overhaul? Many OSS experts love being archaeologists, down on their knees, carefully brushing off the dust to unearth their OSS fossil and painstakingly preserving it. But modern network operations aren’t archaeological digs. We can’t just make educated guesses […]