

What to Build, What to Drop: A Product Roadmap Scorecard for OSS/BSS Tools that Endure (part 4)
Most OSS/BSS roadmaps today overflow with novelty and buzz. You might even hear the words Agentic AI come up (not that I have anything against
Telcos pour millions into incident and problem management every year.
However, these budgets only kick in after damage is done. Black-swan failures (events or event combinations that have never been seen before) still bypass every safeguard to bring networks down on a regular basis.
What if we could learn from industries like aviation and pharmaceutical research to prevent massive outages before they start?
Improvements in algorithmic assurance tools like AIOps continue to transform how telecoms detect and resolve incidents. Algorithms now scan vast amounts of data to predict and mitigate issues faster than any human could. Unfortunately, a problem still remains. These algos are mostly built on historical data. Black swans (rare, high-impact failures) are by definition, events the algorithms have never seen before.
Even the most advanced anomaly detection can’t pre-empt an outage if no comparable signal exists in the past. That’s why telecoms continue to experience sudden, cascading failures that defy every model and trigger massive disruption.
As discussed in this earlier post about black swans:
“It has recently dawned on me that there are a large proportion of Sev1s (severity 1 incidents that cause significant customer and network impact) and near-misses that are considered “black swan” events because they have never been seen or contemplated by the telco previously. Most telco networks are already incredibly resilient, with a lot of thought being assigned to mitigating potential failure scenarios. They also tend to have multiple layers of resiliency built in (for five-nines – 99.999% availability or higher). Therefore in many cases, Sev1s are actually caused by multiple failures simultaneously (often obscure failures).
By “multiple failures,” I don’t mean failures that cascade from a single issue, but multiple issues arising at once (eg a fibre cut on the working path and then a card failure or software failure that prevents customer traffic from failing over to the resilient / protect path according to the resiliency plan). They’re often multi-domain in nature too, such as an unusual combination of a transmission failure, an outside plant failure, a routing problem, a power failure, weather event, accident, planned change, etc, etc.”
There are two parts to this:
We’ll dive deeper into both of these in this article.
.
By their nature, black swans are only detected reactively, after they’ve already caused an outage or degradation. We need to avoid black swans by becoming better at identifying or anticipating them more proactively.
This is where advancements in large-scale network digital twins are offering great potential. That is real-time virtual replicas of your network, synchronised continuously with live configurations and data flows.
Unlike traditional lab testing, digital twins enable massive “what-if” simulation at digital speed. You can run millions of variant configurations like rare fault combinations, capacity spikes, data corruption, stress / load events or firmware anomalies and discover how your network behaves under those scenarios (eg monitoring of predicted network health / performance or blast-zone tracking). In the virology industry, this approach is called massive in-silico variant testing, which has been critical as a mechanism for fast-tracking testing medicine variants. For example, researchers used high-throughput in-silico screening against thousands of molecules to identify potential inhibitors of COVID proteins.
By applying this concept to telecom networks, we introduce the ability to stop just waiting for failures to occur and start to systematically uncover scenarios that would otherwise remain invisible before the outage appears.
.
Traditional telecom budgets are heavily skewed toward incident response and recovery. As shown in the ITIL framework diagram below, much of our traditional spending sits in yellow areas like Incident Management, Problem Management, and the Service Desk. We literally spend millions on these functions, even though they’re only engaged after an outage happens.
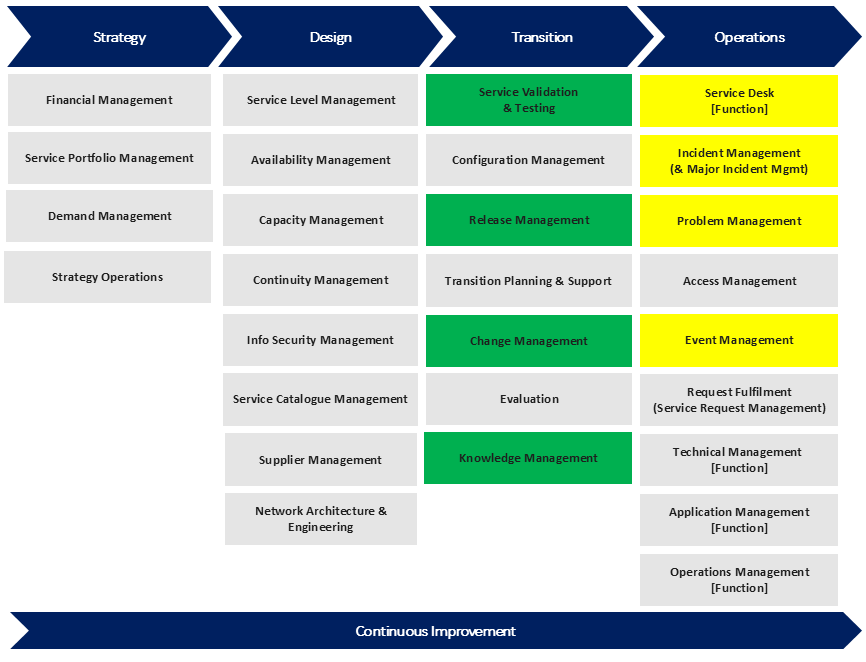
To build true resilience, telcos need to shift investment left. From reactive to proactive.
That means increasing funding for green activities like Service Validation & Testing, Release Management, Change Management, and Knowledge Management. By significantly enhancing our sophistication in these functions, it will hopefully allow us to catch risks earlier in the lifecycle, catch problems in-flight (eg during the release of a change into production), automate validation and embed resilience into every change before/during/after it goes into production (eg blue/green testing).
Over time, this approach reduces firefighting costs and transforms your operating model from crisis response to continuous prevention.
It hopefully takes head-count out of the NOC and into systematic test and release management.
This doesn’t prevent all outages by any means. Cable cuts, equipment failure and other similar events will always happen and will need an incident / problem / event response. What I’m getting at here is the systematic increase in automation percentage (approaching the orange asymptote in the diagram below).

Whilst not specifically coloured in the ITIL boxes above, we could use these techniques to shift even further left and build greater resilience into the Network Architecture & Engineering block in the ITIL framework too.
.
You’ll also notice that the Knowledge Management box is shaded green in the diagram above.
The aviation industry has achieved remarkable safety records by sharing information with others. When a plane crashes (or nearly crashes), every airline, regulator and manufacturer gets access to the incident report. This collective knowledge sharing means the entire ecosystem learns from each event rather than each company repeating the same mistakes.
Telecom could potentially adopt a similar model.
Today, some cross-carrier knowledge is shared, such as network vendors sharing information and patches across their customer-base. As mentioned earlier, most intra-domain problems tend to already well contained by the vendors.
The black swan problem tends to arise from multi-domain scenarios. Since every carrier’s network is different, it can be difficult to provide sufficient context to capture the true extent of the outage. Similarly, most carriers wish to minimise sharing of outage information as lost trust is one of the biggest reasons for customer churn.
As a result, we need to find an approach for standardising network incident “fingerprints” – a combination of configuration, conditions, and behaviours that create a specific failure scenario.
[Note: To my knowledge, as of now, no universal industry standard exists for network outage fingerprinting specifically. Research has only established frameworks and systematic approaches for fingerprinting network flows, protocols, devices, and attacks. If you’re aware of any incident / outage fingerprint classification, please leave us a note in the comments below]
There also needs to be context tied into this fingerprint. Every simulation / variant run on a digital twin potentially yields a unique fingerprint. By capturing these fingerprints in a standardised format and anonymising sensitive data, telcos can contribute to an industry-wide repository of known and simulated failures. Perhaps it even becomes a repository for automated testing prior to going into production with a network/system/solution change.
Before any production change, teams can consult this shared database to determine whether anyone, or any simulation, has seen this pattern before? If a match exists, safeguards can be implemented or changes redesigned before rollout.
As an aside, a client once described their Change Review Board (CRB) as a “mothers club meeting” because they felt there was little evidentiary information being used by the CRB to decide whether to authorise a change.
The shift-left + fingerprint approaches should help to provide much better pre-change intel for CRBs. In the modern paradigm of continual release, we can potentially even automate the CRB process.
.
.
In a world where software and virtualisation are speeding up the cadence of change in our networks, proactive simulation is not a nice-to-have. It’s an undeniably necessary evolution. By borrowing proven strategies from aviation and medical research, the telco industry can pre-empt black swans instead of merely reacting to them. With digital twins, massive scenario testing and shared knowledge, we can finally make resilience an inherent property of your network (before the next outage starts)… which leads to a final point for you to ponder…
Critical infrastructure in telco networks (eg critical links or structurally important nodes) often have duplicate or even triplicate protection mechanisms. Could these approaches even identify opportunities to reduce the significant infrastructure costs of making the network more resilient? Obviously this technique can’t prevent a cable cut, so a critical link will still need a working and protect fibre path. However, I’m wondering whether you might be able to think up any other scenarios where these approaches could reduce infrastructure costs.

