Most OSS experts focus on the implementation and post-go-live performance aspects of a transformation. That makes perfect sense, because they’re the most visible phases. But by the time implementation begins, many of the decisions that shape success or failure have already been set in place. The pre-implementation phase is often underestimated – treated as a […]
Telco keeps talking about being scared of an imminent skills cliff. But perhaps the real problem is not just that experienced people are leaving. It’s that the industry has stopped feeling like the natural destination for the next generation of brilliant minds. Meanwhile, the industry’s hardest problems – automation, AI-native operations, complex transformation, data integrity, […]

Phone books now look like a relic from another era. Stone. Cold. Dead. But they were once one of the most powerful business growth engines in the world. Owned by telcos! As they declined in importance, Telcos didn’t just lose a directory. They totally forgot they were matchmakers. Phone books were never just paper directories. […]
I have a really important question for you to ask yourself today. It’s a question that shapes a lot of our thinking about how I can help the OSS/BSS/telco industry. How does what I do make more money for clients? Not just what your company does. Not what your brand says on the website. Not […]

We’re releasing our latest report today. Click on the image below to download it. Why are transformation approvals (eg business case approvals, vendor selections, project transformation decisions) forced to look perfect when delivery is anything but? That is the quiet contradiction at the heart of many (most?) digital transformation programmes. We build business cases as […]
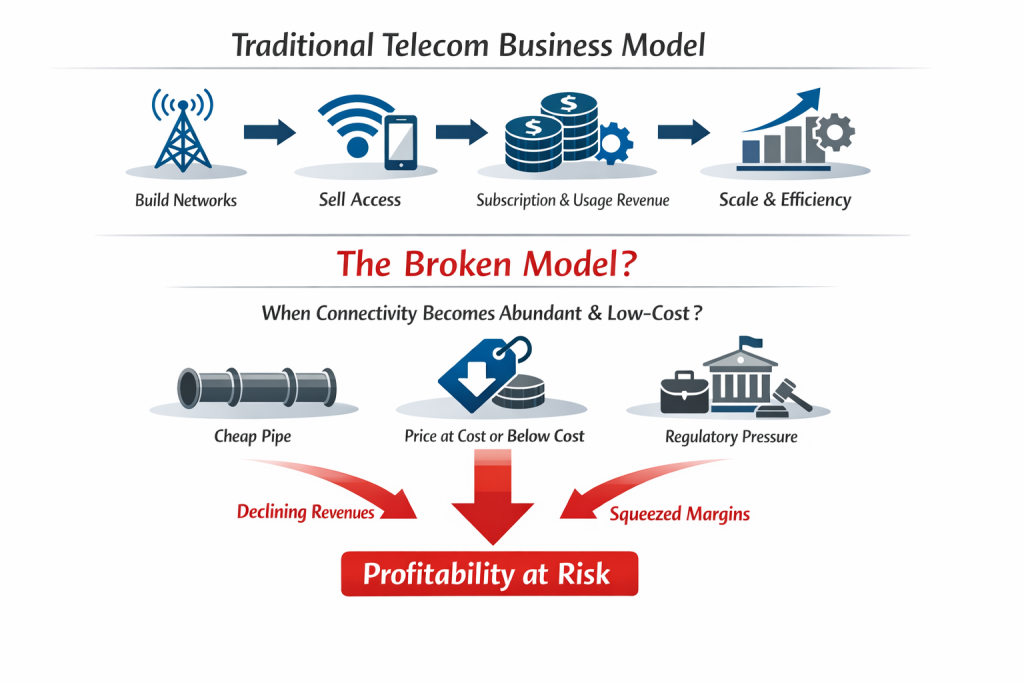
As seen in the diagram, for most of telecom history, the core business model has been simple: Build networks Sell access to those networks Recover capital (revenue) through subscription and usage revenues, and Protect margin through scale and operational efficiency But what happens if (when? after?) that model breaks? What happens if connectivity becomes so […]
With MWC upon us again, I thought I’d pose a question about how our industry, and the 500+ OSS/BSS vendor market within it, is currently evolving. Telcos spend billions on transformation programmes every year. They talk about massive disruption like cloud-native stacks, open architectures, AI-driven automation and next-generation digital experiences. On paper, it sounds like […]
Quants have become the rockstars of modern share trading – extracting powerful signals from oceans of data at near real-time speed. Trading firms invest billions in them and in infrastructure that will give them even the slightest timing edge. Yet while telcos drown in dashboards, the next competitive advantage may belong to the “NOC-star” – […]
One of the things I find incredibly interesting when I look at the Simplified TAM diagram below is that of each of the arrows indicating a workflow, only one has systems that aren’t really designed to manage the operational workflow. Assurance has trouble tickets Fulfilment has service orders Field operations has work orders Even billing […]

What happens when a Software Engineer, Enterprise Architect and Network Ops Engineer walk into a bar?….. . You know that head-slap moment when you realise software is more hindrance than help? I had one such experience back in circa 2005, when I watched a genuinely brilliant network ops engineer spend an entire afternoon navigating tools […]
Have you ever wondered why there’s such a big deal made of the start of a marriage (there’s a whole industry built around engagements and weddings), but there’s almost no fanfare at the end? Samuel Thompson pointed this out on Greg Isenberg’s podcast. Samuel highlighted that there are lots of products designed for the start […]

Whether we like it or not, most of us judge books by their covers. Sometimes that’s visual. Sometimes it’s the title. But here’s a thing I find interesting. Having written a couple of books myself, a lot of thought goes into choosing the title to resonate with the viewing audience. And yet, sometimes a title […]

We speak with buyers and sellers every week, and one word keeps repeating. Trust. It keeps appearing in buyer conversations and seller conversations alike. It’s more than a word though. It’s costing the telco industry millions. When trust is missing, 18-24 month buying cycles become the default. This is the Buyer – Seller Chasm that […]

We’re already seeing it. AI is slowly infiltrating telecom, one little project at a time… monitoring, automating, optimising. In AI, we have one of the most disruptive opportunities of our lifetime, but the results of telco AI projects to date still feel eerily familiar. Are most telcos using tomorrow’s tools with yesterday’s thinking? Maybe the […]

We know telco customers want faster speeds.But is it possible that we’re focussed on the wrong type of speed?Here’s a hint: the real drag isn’t line-speed. . “Finally”: The Message that Triggered an Article Late last week a friend pinged me with a SpeedTest screenshot and a single word: “finally.” I was confused. At first […]

Ever noticed how many OSS decisions are made by people who have never set foot on site? What if your single most powerful OSS upgrade this year is a day riding shotgun with field techs in a hi-viz vest? This article digs into the quiet damage that OSS experts with a total lack of field […]

Are you frustrated by the complexity of your OSS/BSS factory? With hundreds or even thousands of systems, all trying to juggle thousands of activities without dropping the ball is like organised chaos. But what if we’re looking at it all wrong, both in the way we’ve always designed our legacy application architectures and how we’re […]

The story of Berkshire Hathaway is a famous one. It started in textiles but Warren Buffett chose to drastically change strategy because the textiles industry was dying. You’d have to say his decision has proven to be correct. If it stayed in textiles, Buffett would almost certainly not be as famous as he is today. […]
You’re in the business of OSS sales (we’re all in the business of OSS sales if we want to work on an OSS project). Your OSS sales assets are full of facts, features and benefits. That fits perfectly for every buyer who thinks and says their procurement decisions are logical and calculated. Just one problem: […]
If asked to think about telco’s most valuable assets, most people think spectrum, networks and customers. But if we think a bit more laterally, telcos have other compounding growth engines that are never discussed, to the point of being invisible. In fact, the assets that have the potential to compound fastest probably don’t even appear […]