


Can you predict the Next 40 years of OSS/BSS? The Lindy Effect might help
When you’re planning your next-generation OSS/BSS roadmap, what’s guiding your decisions? Are you looking for and/or researching features that have never been seen before? Are
After a major outage, we conduct PIRs (Post Incident Reviews). If we find something, we usually add controls.
But when you think about it, that’s a bit like bandages on an infected wound – more layers, more failure points and potentially even a wider blast radius. The durable fix is more clinical: identify and remove the dead tissue. Investigate deeper and find ways to retire brittle integrations, delete failing components, simplify the solution.
Subtraction, not addition, could be the best reliability upgrade, but how often do we even consider that in a PIR? Is subtraction listed in your PIR template?
This is part 2 in a series that builds upon the Lindy effect, long-tail and complexity/friction factors. (part 1 here)
.
Is it just me, or are we seeing more catastrophic network failures make it onto the front page of our news feeds lately?
I have a sneaking suspicion that two long-term trends are colliding.
First, have you noticed that almost every wave of “next-gen” technology has added another layer on top of what already exists. Each abstraction layer brings its own data models, identifiers, failure states and operational tools. Just like the modified TMN Pyramid below, each of these new standards aims to abstract and connect.

There’s no doubting that this has benefits (it remove complexity from underlying systems and connect adjacent systems to provide greater contextual awareness / control). But as the diagram above shows, the abstraction makes it harder to connect the dots in a fault-fix situation. We lose the north to south, east to west visibility in the virtualisation fog. This is particularly true when it comes to the physical layer, which generally doesn’t have pollable APIs to provide status updates (and needs the OSS to provide some sort of record of awareness).
As an example, this triptych below shows the type of complexity that’s introduced by the SDN / NFV virtualisation layer. The increased management complexity is discussed in this old article.
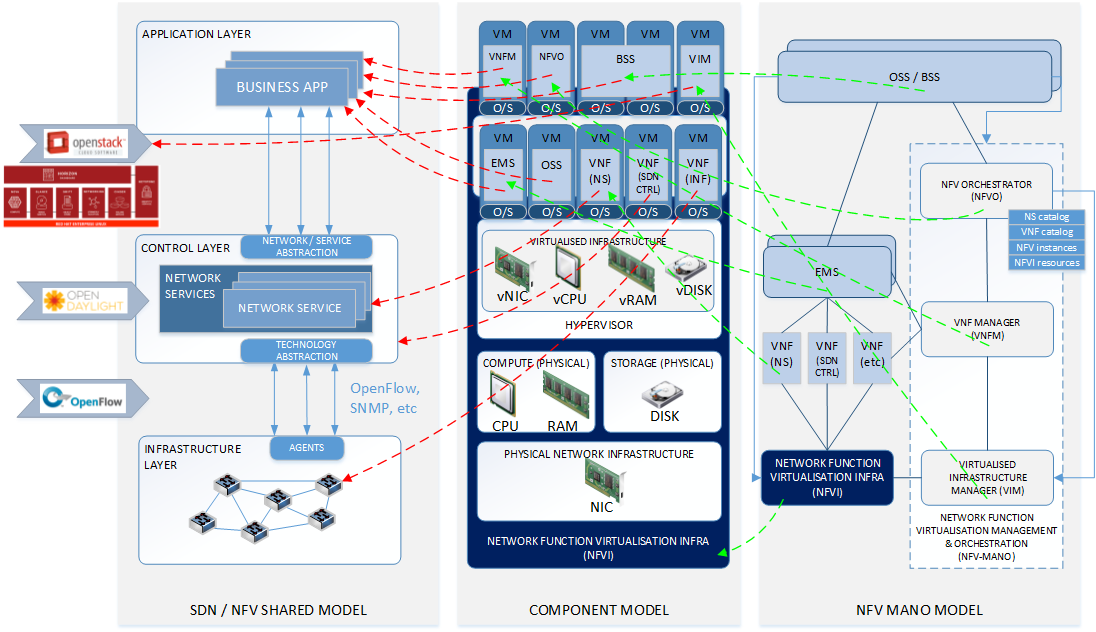
It gets a bit complex.
Second, most Western network operators now have fewer hard-core engineers who know the stack top-to-bottom, end-to-end. Deep in-house expertise has retired, been outsourced, segmented, or been replaced by black-box platforms and automations. The path to being a network ninja has been dissected.
The net effect is a larger technology surface area to understand, test and maintain – but with fewer people who can understand all the moving parts. In that environment, any new control you add post-incident is just one more variable for the night-shift operator to retain in their head when things break at 3am.
.
Most “black swans” aren’t. Well, not exactly. They’re probably not black swan events in isolation, but probably are as a unique combination. We recently had the chance to perform a network resilience study on an iconic telco’s networks, systems, people and process. Almost every one of their Sev1s in the last few years were from combinational, multi-domain effects. They are multi-factor failures where mid-flight changes, undocumented network fixes, old integrations, obscure configurations and variant-heavy workflows or API integrations lining up just wrong.
Rather than looking at outages as something to rapidly triage and patch (which we should continue to do), we can also consider them to be like X-rays. Like X-rays, they reveal what’s really broken, the real dependencies that OSS/BSS data, documentation and architecture diagrams gloss over.
In our case, those X-rays shouldn’t just be discarded as soon as the quick-fix is in place. Instead, capture them. Reconstruct the exact failure path: which systems, which data, which software versions, which processing steps, which fall-outs, etc have been invoked. Mark every hop where ambiguity, duplication, or faulty bespoke logic crept in. That map is your shortlist of things to remove or simplify (or if not those, rectify).
.
To turn a one-night incident into durable learning, pair the PIR with a structured checklist. The Friction Continuums give you a way to classify and prioritise where complexity accumulates.

We can use it to tag each element in the failure path across the following buckets:
For each friction point, try to generate a subtraction proposal that minimises the outage threat surface, not just a mitigation. Think of ways to reduce failure combinations.
.
Compensating controls do the opposite. They tend to add even more obscure and undocumented variants into the mix. This adds lack of full contextual understanding, latency, state and new failure points. It might feel like progress because a new fix is deployed, but the underlying variant trap remains (and even grows).
What to remove first after an incident
Make “delete something” a standing item in every PIR. Prioritise removals that permanently cut failure combinations and speed up future changes:
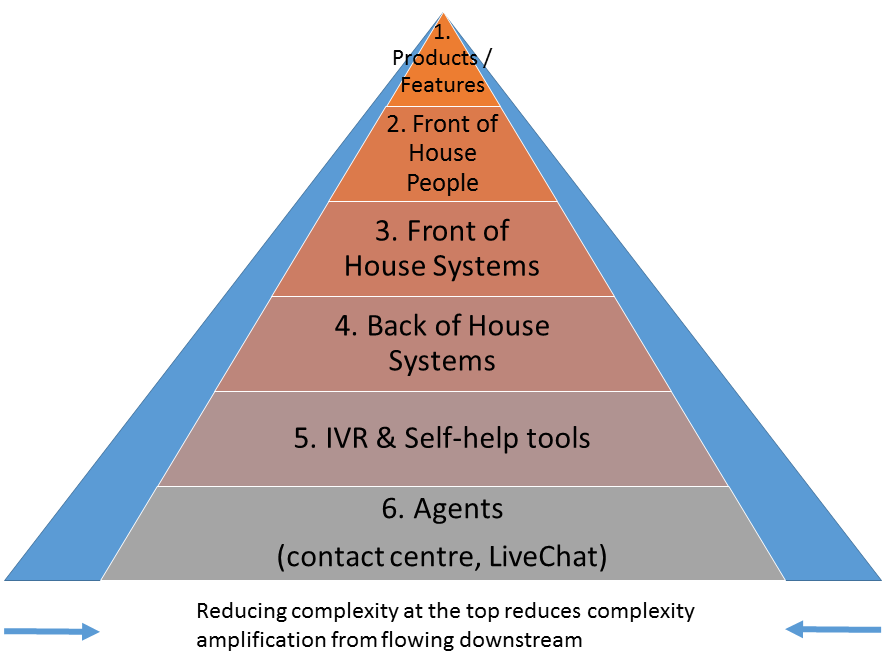
.
Outages are brutal, but they are also honest. They expose where complexity, data integrity failures and friction have quietly accumulated (and perhaps where a backhoe is working).
The Lindy Effect gives us the north star on what to retain: clarity on what will still matter in ten years. The long-tail lens give us a guide on what to remove. Together, they turn each incident into a subtraction opportunity – fewer parts, fewer surprises, faster change, lower MTTR.
If Lindy tells us what to keep and the long tail tells us what to cut, the Friction Continuum tells us where to start. Map the failure path, tag the data, process, integration, and organisational frictions. Reliability grows when friction and complexity shrinks.
In the next article – Rebuilding or Renovating – we look to the Porsche 911 and Microsoft Office for cues to taking the logical next step.
