


The Age-Old IT vs OT Debate: Who gets the Keys to Your OSS?
For decades, organisations have argued over whether IT or operations (OT) teams should control the OSS environment, as though it’s a binary decision. Giving one
“Unlike data, there is little mainstream computerised support for modelling and analysing systems.”
Mark Zangari in his lecture to San Francisco Uni.
As Mark Zangari points out, there are many different tools for assisting our brains to process data (who could’ve missed all the hype about Big Data tools for example or Business Intelligence or Data Mining, etc), but there aren’t so many decision support tools that help the human brain to process systems or workflows.
In other words, we’ve mastered the ability to manage data (the “data” box in the diagram below) and present it in useful forms including graphs and charts (point 1 in the diagram). This is the output of common Business Intelligence tools.
However, this data is often not effective as a basis for making decisions because it doesn’t consider the complex interplay of factors in our environments or systems (the “Systems Analysis” box below). It doesn’t tend to adequately identify the optimal balance of inter-related variables.
As Mark points out, we rely on our brain and/or gut-feel to resolve the complex implications to go from point 1 to point 2 (the systems analysis box) and then make informed decisions. Our brains are quite good at interpreting graphs, but not very good at performing complex systems analysis to make decisions.

The “Data” box has largely been solved, but there are very few tools available to help solve the “Systems Analysis” box for the layperson. We’ve solved the big data, but not the big picture.
As described in an earlier post describing a theoretical decision support feedback loop, I believe this to be a huge area of interest for OSS operators. Decision makers at CSPs, integrators, consultants, etc need tools in the System Analysis box to aid with decision support. Not always just for once-off decisions, but for the same approach to also offer a streaming workflow of decision support as inputs keep coming into the left-side of the pipeline in near-real-time.
We should note that OSS workflows are often so complex and have so many branches in the decision tree, that even highly experienced operators can’t provide optimally efficient outcomes. To put this into the context of a standard distribution curve (see below), your new starters are probably making more errors than the norm (ie -1 Standard Deviations) whilst your most experienced operators are probably making decisions slightly better than the norm (ie +1 SD).
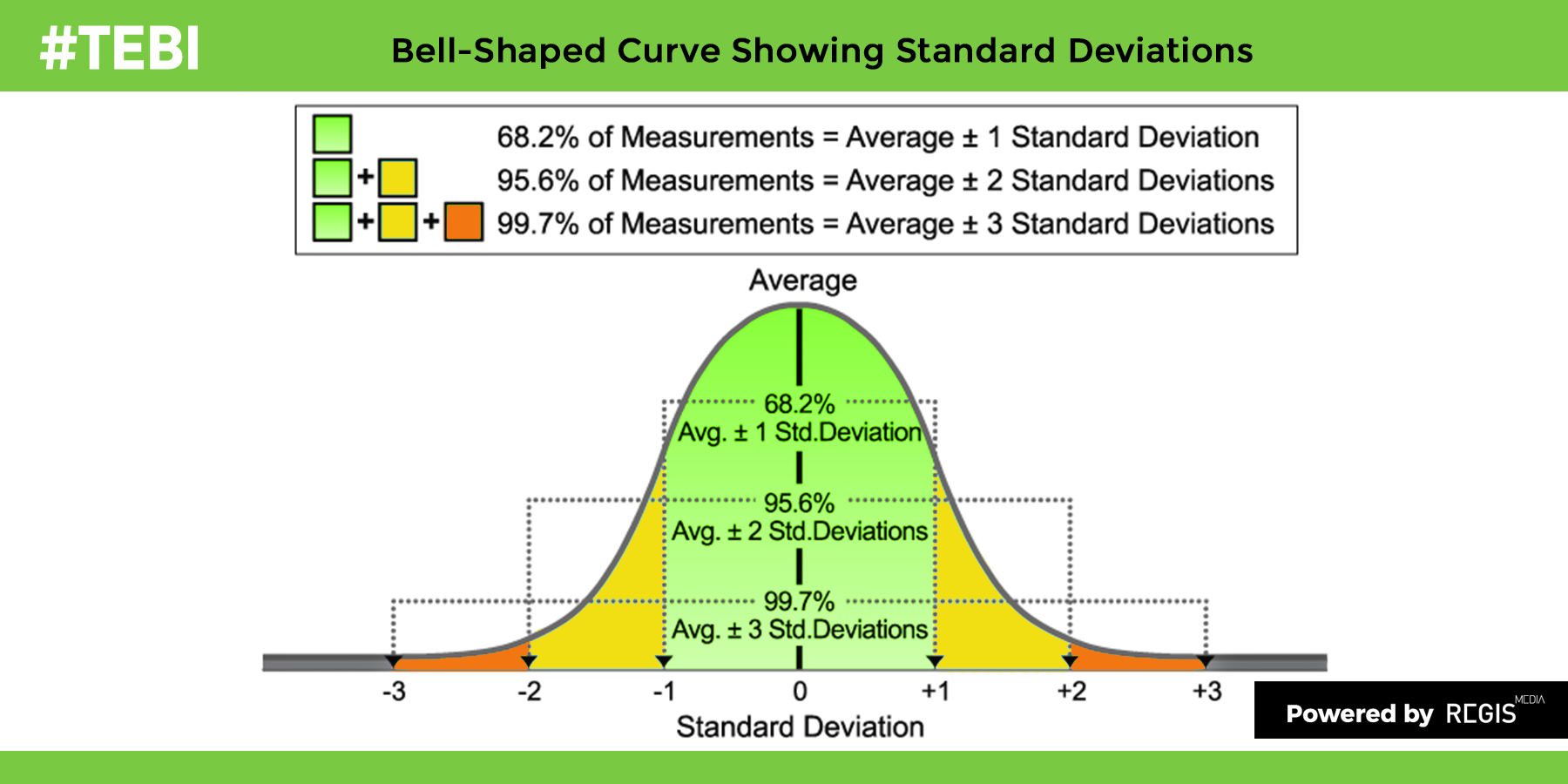
The idea behind DSS (Decision Support Systems) is to provide your operators with automated decision support that helps lift all operators into the +2 SD range when making decisions using your OSS tools (becoming the new norm).
Have you ever prepared such a bell curve that shows the performance of your operators (or your customers) at their day-to-day tasks? Do you have the tools to measure and improve their performance?
BTW, the link to Mark’s lecture is also shown in this YouTube embedded link below:


For decades, organisations have argued over whether IT or operations (OT) teams should control the OSS environment, as though it’s a binary decision. Giving one
Given the topical theme of the World Cup final, we’ll go with a soccer story today. For the World Cup final, do you think Argentina
For decades, scale gave large telcos purchasing power, infrastructure reach, extensive capability and millions of customers. It became one of the world’s most powerful and

Success in business, distilled to its simplest form, is often about arbitrage. The gap between supply and demand. The gap between value delivered and value